Over the last weekend, I had some time on my hands and revisited my biking application: https://biking.michael-simons.eu. That application turned 10 this year, started as a Sinatra based Ruby application in 2009 and helped me a lot from the late 2013 and early 2014 in my career. Back then, I was using Spring for a couple of projects, both private and work, and discovered early pre 1.0 releases of Spring Boot.
I found that super interesting. With the impending release of Java 8 in 2014, I found my personal project to work on that year. I had written extensive blog posts about that application (See the entry Developing a web application with Spring Boot, AngularJS and Java 8. This posts culminated not only in an application i used nearly everyday, but also in my very first book, Arc42 by example (which is also on Packt these days).
Furthermore, the application brought me very close to the Spring Boot community. By following Spring Boot with this application, upgrading and evolving it with every release, I was able to spot issues, report them and sometimes fix them. It literally change my career.
Having said all that: Why rewriting a major part of my application? As I said, the thing was also to learn more about Java 8, about the stream API, lambdas and whatnot. I really went nuts with the streams API.
Building up an analytic query
The main feature I use is tracking my mileage. I wanted it be as simple as possible: Have a look at the odometer of each bike, add the number with a date to the bike, done. The application shall than display the difference between the recorded value of last month with the next month. So, that’s basic arithmetic, but if you want to compute the date for the following chart (available here), good luck with that:
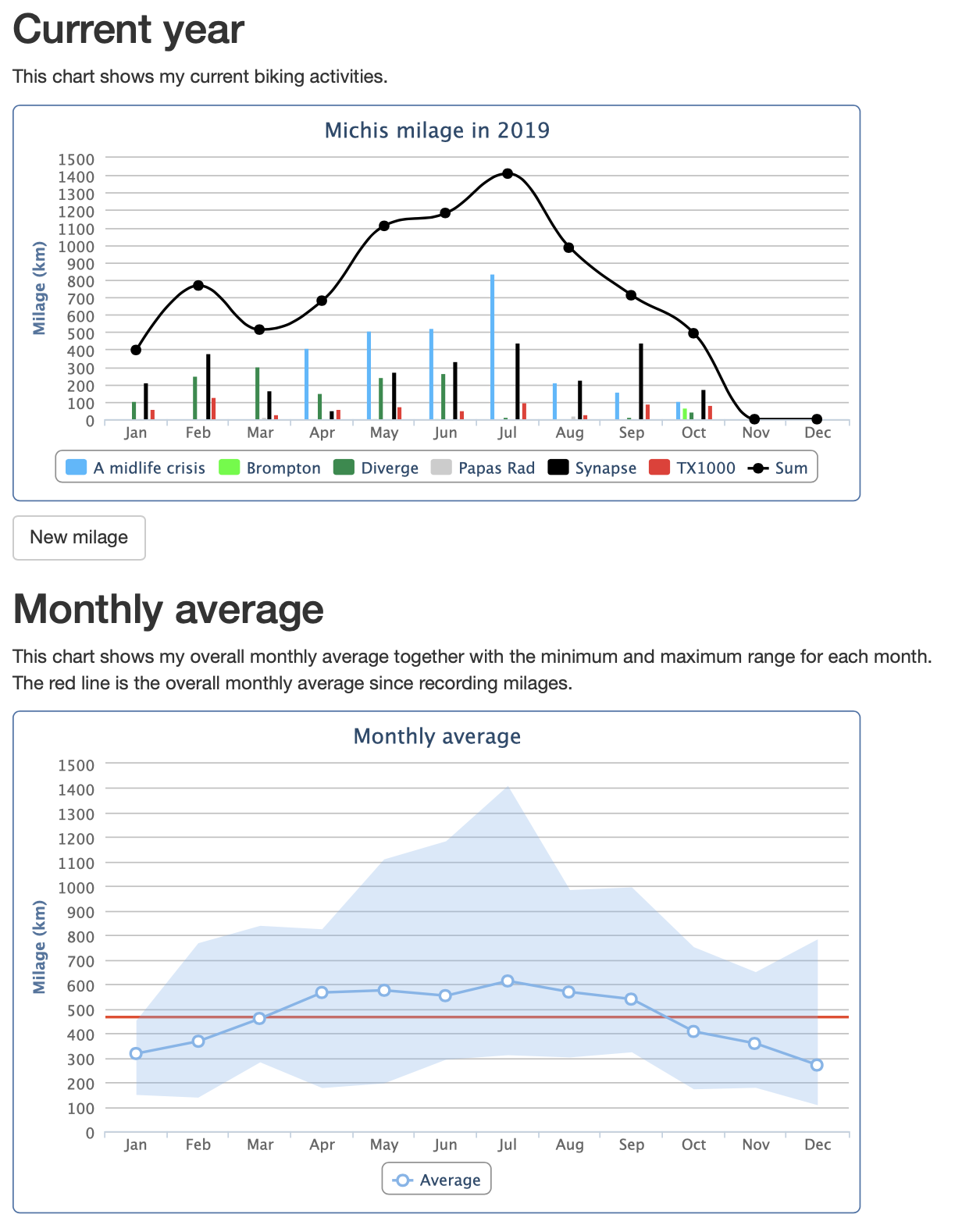
What do we see? The upper chart shows the mileage per bike per month I rode with a summarising line over all bikes per month. The lower chart shows the lowest and highest total value per month, the average monthly value and the overall average over all years per month (the red line).
I don’t aggregate the values, I did compute them all from the periods mentioned above.
Here’s just the tip of what I needed to do to have only the data to work with: Building the period values itself (the difference between a month and the next), stored in a transient attribute:
public synchronized Map<LocalDate, Integer> getPeriods() { if (this.periods == null) { this.periods = IntStream.range(1, this.milages.size()).collect(TreeMap::new, (map, i) -> { final MilageEntity left = milages.get(i - 1); map.put( left.getRecordedOn(), milages.get(i).getAmount().subtract(left.getAmount()).intValue() ); }, TreeMap::putAll); } return this.periods; } |
And then working with it, like this to summarise those periods:
public static Map<LocalDate, Integer> summarizePeriods(final List<BikeEntity> bikes, final Predicate<Map.Entry<LocalDate, Integer>> entryFilter) { return bikes.stream() .filter(BikeEntity::hasMilages) .flatMap(bike -> bike.getPeriods().entrySet().stream()) .filter(Optional.ofNullable(entryFilter).orElse(entry -> true)) .collect( Collectors.groupingBy( Map.Entry::getKey, Collectors.reducing(0, Map.Entry::getValue, Integer::sum) ) ); } |
There have been a couple more of those plus a ton of test code. This is nice when you want to play around with the stream API and such, but to be honest, really?
I have been speaking about SQL and jOOQ since 2016. Back then, I was already working ENERKO Informatik for a long time. We had been a database shop right from the start. It was there where I learned that is a good thing to put your database to work for you and not the other way round. At times, I was not convinced, but these days I believe in that approach more than before. And that is true regardless whether you use a relational or graph database.
Here’s one of the later installments of that content:
So let’s have a look at what is needed for the charts. First of all, the individual monthly values: This can be solved using a window function, in this case, the lead function:
SELECT bikes.name, bikes.color, milages.recorded_on, (lead(milages.amount) OVER (PARTITION BY bikes.id ORDER BY milages.recorded_on) - milages.amount) VALUE FROM bikes JOIN milages ON milages.bike_id = bikes.id ORDER BY milages.recorded_on ASC |
This query joined the bikes and their recorded milages and moves the window over a set of two rows following each order, the order being when they have been recorded. lead gives a following row at offset 1 by default. And just with that, I can compute the difference. 5 lines, without the additional selected columns. That was easy.
I can create a SQL view from that, if I want. The query is actually needed for all the charts.
I cannot add another aggregate function on top of the window function, at least not in H2, so I need to manually aggregate to values per bike per month to a monthly value.
This is easy. Assume for a moment, there’s a table like thing monthlymilages containing the above query. We do this:
SELECT monthlymilages.recorded_on, SUM(monthlymilages.value) VALUE FROM monthlymilages WHERE VALUE IS NOT NULL GROUP BY monthlymilages.recorded_on |
sum is an aggregate function, so we need to group by the month.
Now, let’s pretend that this is a table like thing named aggregatedmonthlymilages. We then can select everything we want by slapping a bunch of aggregates on it:
SELECT EXTRACT(MONTH FROM aggregatedmonthlymilages.recorded_on) MONTH, round(MIN((aggregatedmonthlymilages.value))) minimum, round(MAX((aggregatedmonthlymilages.value))) maximum, round(avg((aggregatedmonthlymilages.value))) average FROM aggregatedmonthlymilages GROUP BY MONTH ORDER BY MONTH ASC |
And that’s just it. Views are bit static and I would probably need additional columns to join them and also have to maintain them. I prefer something called a Common table expression. That sounds complicated, but it is simple to use with the WITH clause:
WITH monthlymilages AS ( SELECT bikes.name, bikes.color, milages.recorded_on, (lead(milages.amount) OVER (PARTITION BY bikes.id ORDER BY milages.recorded_on) - milages.amount) VALUE FROM bikes JOIN milages ON milages.bike_id = bikes.id ORDER BY milages.recorded_on ASC ), aggregatedmonthlymilages AS ( SELECT monthlymilages.recorded_on, SUM(monthlymilages.value) VALUE FROM monthlymilages WHERE VALUE IS NOT NULL GROUP BY monthlymilages.recorded_on ) SELECT EXTRACT(MONTH FROM aggregatedmonthlymilages.recorded_on) MONTH, round(MIN((aggregatedmonthlymilages.value))) minimum, round(MAX((aggregatedmonthlymilages.value))) maximum, round(avg((aggregatedmonthlymilages.value))) average FROM aggregatedmonthlymilages GROUP BY MONTH ORDER BY MONTH ASC |
And that’s all that’s needed for the monthly average chart. 28 readable lines. When you see the query fully upfront, it may is intimidating, but I think show the steps leading to it, is not.
So, in a first commit, I removed all the application site computation and added a new `StatisticService` that encapsulates all database access that does not go through JPA away: Introduce SQL based statistics service.
Migrations and more possibilities
Of course I wanted to keep tests and those tests now should use the same database that I ran in production. I’m actually using H2 (file based) in production, so I didn’t have the need to go for Testcontainers. H2, really? Yes, really. The application runs on a standard hosting provider and I didn’t want to bother with database installation and H2 actually offers all the modern SQL features mentioned above. Luckily, as they are standard SQL, I could switch to another database as well anyway.
But for the tests, I need a schema and data. As I didn’t want the test be dependent on the schema derived from my entity classes, I also added Flyway and a bunch of simple DDL scripts, which you find in the commit as well.
Now with migrations in place I actually can control (nearly impossible with Hibernate auto ddl), I could address something else: I used the relation between bikes and milages to compute the last mileage for a bike as a property I gave out as JSON. So either I would need an eager association or use “open session in view” for Hibernate to make that work at the web layer: In that commit I added a computed column that I filled with the value I want. The column is now updated when adding a new milage and that’s fine to have some denormalisation.
Also: Be really careful if you have “open session in view” in your Spring application: If at some point you decide to disable it and rely on your @WebMvcTests using mocked repositories, that tests won’t fail, as they don’t need a Hibernate session at all.
Now jOOQ
So, I had the queries and I could finish, right? When I would change the schema, my tests would break and I would need to go through all query strings to fix things. That’s not something I want.
So, in “Introduce jOOQ” I added jOOQ to the build, including a temporary migration into a temporary database beforehand which generates a Java based schema for me, pretty much exactly like described in the slides at the start.
Please, have a look at the slides for an introduction. For this post, I’m gonna focus on the benefits I got.
First, I can store fragments of SQL on variables, first the computation of the monthly values, as a table like thing:
/** * The computed monthly milage value. */ private static final Field<BigDecimal> MONTHLY_MILAGE_VALUE = lead(MILAGES.AMOUNT).over(partitionBy(BIKES.ID).orderBy(MILAGES.RECORDED_ON)).minus(MILAGES.AMOUNT).as(ALIAS_FOR_VALUE); /** * The cte for computing the monthly milage value. */ private static final CommonTableExpression<Record4<String, String, LocalDate, BigDecimal>> MONTHLY_MILAGES = name("monthlyMilages").as(DSL .select(BIKES.NAME, BIKES.COLOR, MILAGES.RECORDED_ON, MONTHLY_MILAGE_VALUE) .from(BIKES).join(MILAGES).onKey() .orderBy(MILAGES.RECORDED_ON.asc())); |
This is compiled Java code based on the database schema. If the schema changes, the code won’t compile. There is no string concatenation going on. The code knows both SQL and my schema.
For the fragments shared, I used static instances. The code get’s nicer with JDK 11’s var keyword:
var aggregatedMonthlyValue = sum(MONTHLY_MILAGES.field(MONTHLY_MILAGE_VALUE)).as(ALIAS_FOR_VALUE); var aggregatedMonthlyMilages = name("aggregatedMonthlyMilages").as(DSL .select(MONTHLY_MILAGES.field(MILAGES.RECORDED_ON), aggregatedMonthlyValue) .from(MONTHLY_MILAGES) .where(MONTHLY_MILAGE_VALUE.isNotNull()) .groupBy(MONTHLY_MILAGES.field(MILAGES.RECORDED_ON))); var value = aggregatedMonthlyMilages.field(aggregatedMonthlyValue); var minimum = round(min(value)).as("minimum"); var maximum = round(max(value)).as("maximum"); var average = round(avg(value)).as("average"); var month = extract(aggregatedMonthlyMilages.field(MILAGES.RECORDED_ON), DatePart.MONTH).as("month"); this.database .with(MONTHLY_MILAGES) .with(aggregatedMonthlyMilages) .select(month, minimum, maximum, average) .from(aggregatedMonthlyMilages) .groupBy(month).orderBy(month.asc()) .fetch(); |
And there’s the query again, this time type safe and in Java with the added benefit, that jOOQ knows which database I know and potentially can translate some methods and clauses for me that work different in different databases.
What about your day job with that database company?
So, I work for Neo4j since nearly 2 years now and I have giving some talks about using a graph database and why you could use it but I never said use it for everything. I am however very consistent with my opinion on query languages: Use them, they are powerful!
Luckily, in this project here I can do both: SQL in my application and Cypher, Neo4j’s query language, that currently inspires the GQL standard.
How is this possible? I use jQAssistant to verify the architecture of my application. With the changes in the application, I needed to adapt the rules. Rules written in Cypher, as jQAssistant stores the graph of the projects structure as a… Graph 🙂
So this is how the rules of package dependencies looks:
MATCH (db:Package:Database) WITH db MATCH (a:Main:Artifact) MATCH (a) -[:CONTAINS]-> (p1:Package) -[:DEPENDS_ON]-> (p2:Package) <-[:CONTAINS]- (a) WHERE not p1:Config and not (p1) -[:CONTAINS]-> (p2) and not p2:Support and p2 <> db and not (db) - [:CONTAINS*] -> (p2) RETURN p1, p2 |
I have one Java package, where the jOOQ classes are stored. That is my database package which I select first. That’s the first part. The second part in this query – after the WITH clause that has a different meaning than in SQL (here it acts more like a pipe) – makes sure, that each top level package only depends on inner packages or on the support or database package.
Conclusion
In regards of lines of codes, I have now a bit more lines, mainly because I added some more domain objects to pass the series data around. If I subtract them, I save about 1000 lines Java code to compute and test my statistics.
In regards of the domain, I have now better statistics than before: I also have a table storing assorted trips. Trips done on rental bikes etc. I didn’t add them to the original statistics… Because to complicated to add.
Just queuing them and adding them to the sums was way easier. I’m quite happy with the result and I would do it again.
I really recommend that when you are using a database, relational or graph, and your application requires statistics, recommendations, detection of clusters and what not: Use the database at your hands. Don’t try to compute stuff on your own. You hopefully chose a product for a purpose, so make use if it.
I dedicate that post to my former colleagues Silke and Rainer at ENERKO Informatik, I’m happy that I have all that knowledge about query languages and a sense for when it’s useful to use or not.






No comments yet
Post a Comment