DOAG Konferenz und Ausstellung 2016
13 years ago, I visited my first IT conference ever, the DOAG in Mannheim 2003. This year, I will be speaking myself at #DOAG2016 about creating database centric applications with Spring Boot and jOOQ in German (see abstract below).

After a successful premier of speaking in the IT circus earlier this year at Spring I/O about custom Spring Boot starters (btw, I’m also at W-JAX this year with a refined version of that talk), I’m really happy to be accepted at DOAG.
I’ve been very deeply into all things databases since the beginning of my career. My company runs several applications which changed their faces many times over the last decade, but the relational model stood the test of time, often only added to, never completely rewritten.
When visiting DOAG in 2003 and later my company was looking for alternatives to Oracle Forms 6i, whose end off error correction support was announced for the end of 2004 and extended support ending 2008.
Back then we where depending on Client / Server support and Oracle Forms 9 only available as a 3-tier architecture wasn’t an option for us.
I saw lot of different approaches: The whole J2EE stack (yes, it was called that way back then) which was a nightmare to me, lot of different approaches for automagically converting old Forms applications to new ones or the J2EE or to Java clients, which were working equally bad for us, Oracle ADF, Oracle APEX and so on.
Personally, I spent some time in Ruby on Rails land (being back in Java land since 2010), my company opted for Java Swing where desktop clients where needed and Grails respectively pure Spring / Spring Boot with various view technologies otherwise.
Now, more than a decade later, one powerful and given that power, relatively easy to understand technology stack for database centric application with a nice UI for me is Spring Boot using jOOQ to access the database and rendering a nice UI with Oracle JET.
For me, there’s no easier way to start a modern Webapplication then with Spring Boot. The stuff just works and it has an automatic configuration for jOOQ as well.
For accessing relational databases I’d actually prefer an ORM used together with Spring Data JPA for many tasks, but when it comes to reporting and batch inserting, why not using the power of your database, for which you probably have spent a lot of money for? Why computing it on the application server or even worse, at client side? Here is where SQL shines and jOOQ is really great way to write type safe SQL and throw it your database.
In my demo I’ll use my scrobbled (like Last.FM) music data from the last 10 years to build up a chart reporting engine. The graphs will be rendered inside a simple Oracle JET dashboard.
The demo will facilitate Docker (through the Maven Docker Plugin) for creating the development database instance and will be runnable as a fat jar presenting itself like this:
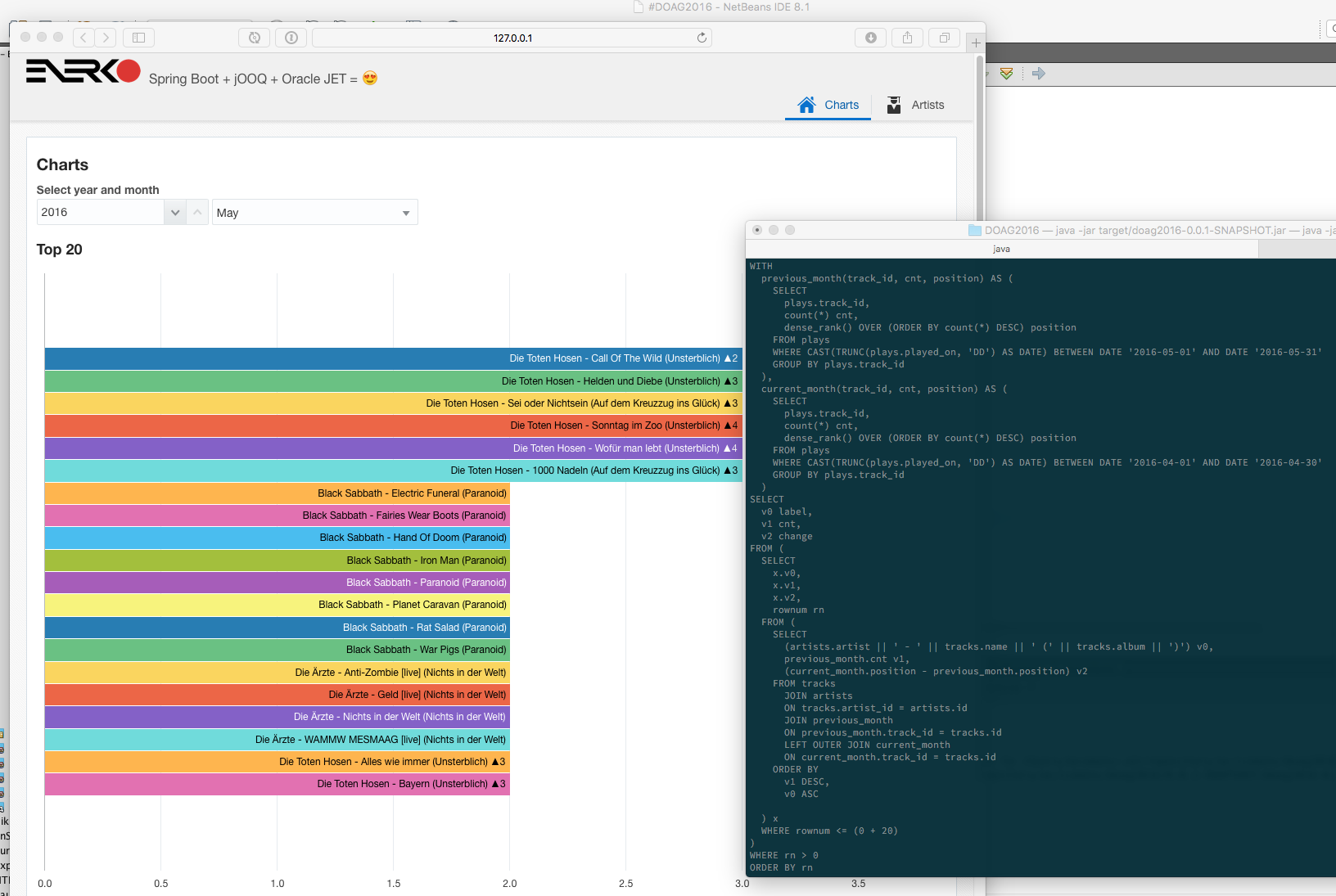
If you want to hear more about that, meet me in Nürnberg, somewhere between 15th an 18th November.
And, as promised, the abstract in German:
Datenbankzentrische Anwendungen mit Spring Boot und jOOQ
In diesem Vortrag wird eine Variante datenbankzentrischer Anwendungen mit einer modernen Architektur vorgestellt, die sowohl in einer klassischen Verteilung als auch “cloud native” genutzt werden kann und dabei eine sehr direkte Interaktion mit Datenbanken erlaubt.
jOOQ ist eine von vielen Möglichkeiten, Datenbankzugriff in Java zu realisieren, aber weder eine Objektrelationale Abbildung (ORM) noch “Plain SQL”, sondern eine typsichere Umsetzung aktueller SQL Standards in Java. jOOQ “schützt” den Entwickler nicht vor SQL Code, sondern unterstützt ihn dabei, typsicher Abfragen in Java zu schreiben.
Spring Boot setzt seit 2 Jahren neue Standards im Bereich der Anwendungsentwicklung mit dem Spring Framework. Waren vor wenigen Jahren noch aufwändige XML Konfigurationen notwendig, ersetzen heute “opinionated defaults” manuelle Konfiguration. Eine vollständige Spring Boot Anwendung passt mittlerweile in einen Tweet.
Der Autor setzt die Kombination beider Technologien erfolgreich zur Migration einer bestehenden, komplexen Oracle Forms Client Server Anwendung mit zahlreichen Tabellen und PL/SQL Stored Procedures hinzu einer modernen Architektur ein. Das Projekt profitiert sehr davon, die Datenbankstrukturen nicht in einen ORM “zu zwängen”.
Nach einer kurzen Einführung dieser Themen wird eine Demo “from scratch” entwickelt, die zuerst die niedrige Einstiegshürde in die Spring basierte Entwicklung mit Java und danach die einfache Verwendung moderner SQL Konstrukte zeigt, ohne das ein ORM oder stringbasierte SQL Statements im Weg stehen. Der Abschluss der Demo wird eine JSON Api sein, die von einer OracleJET Clientanwendung genutzt wird.
Die Besucher kennen im Abschluss eine schlanke Alternative sowohl zur aufwändigen JPA basierten Entwicklung als auch zu APEX Anwendungen.

