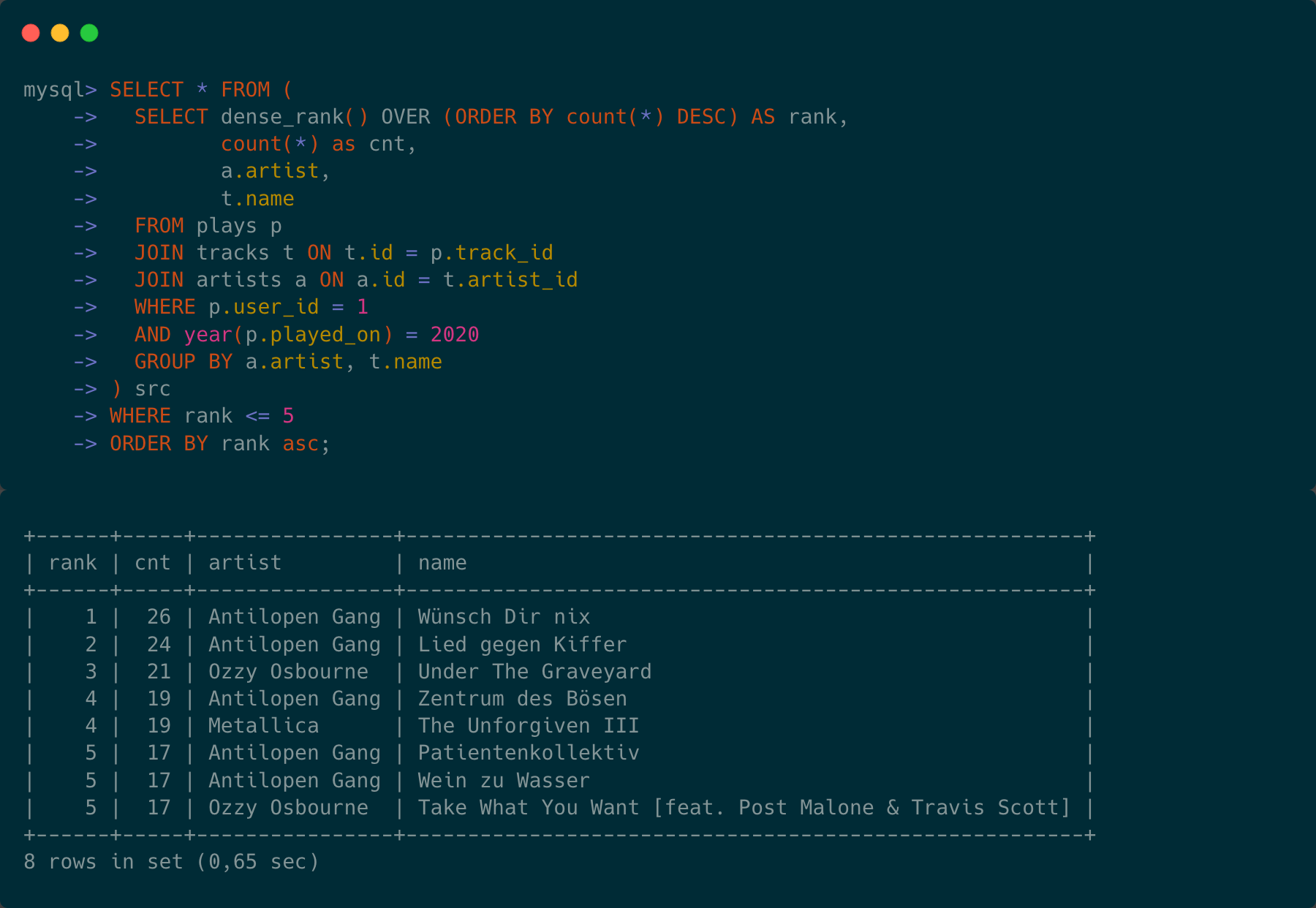
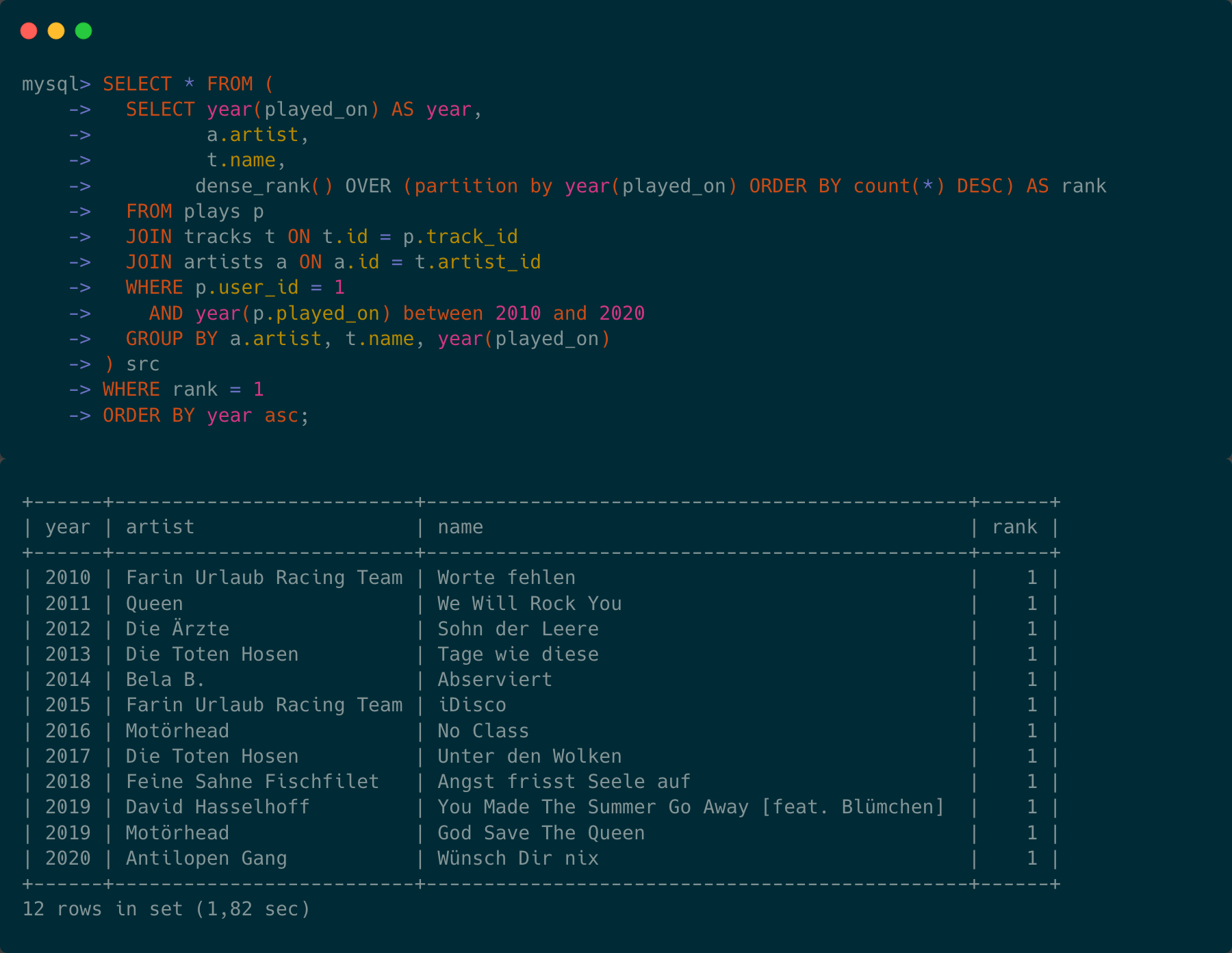
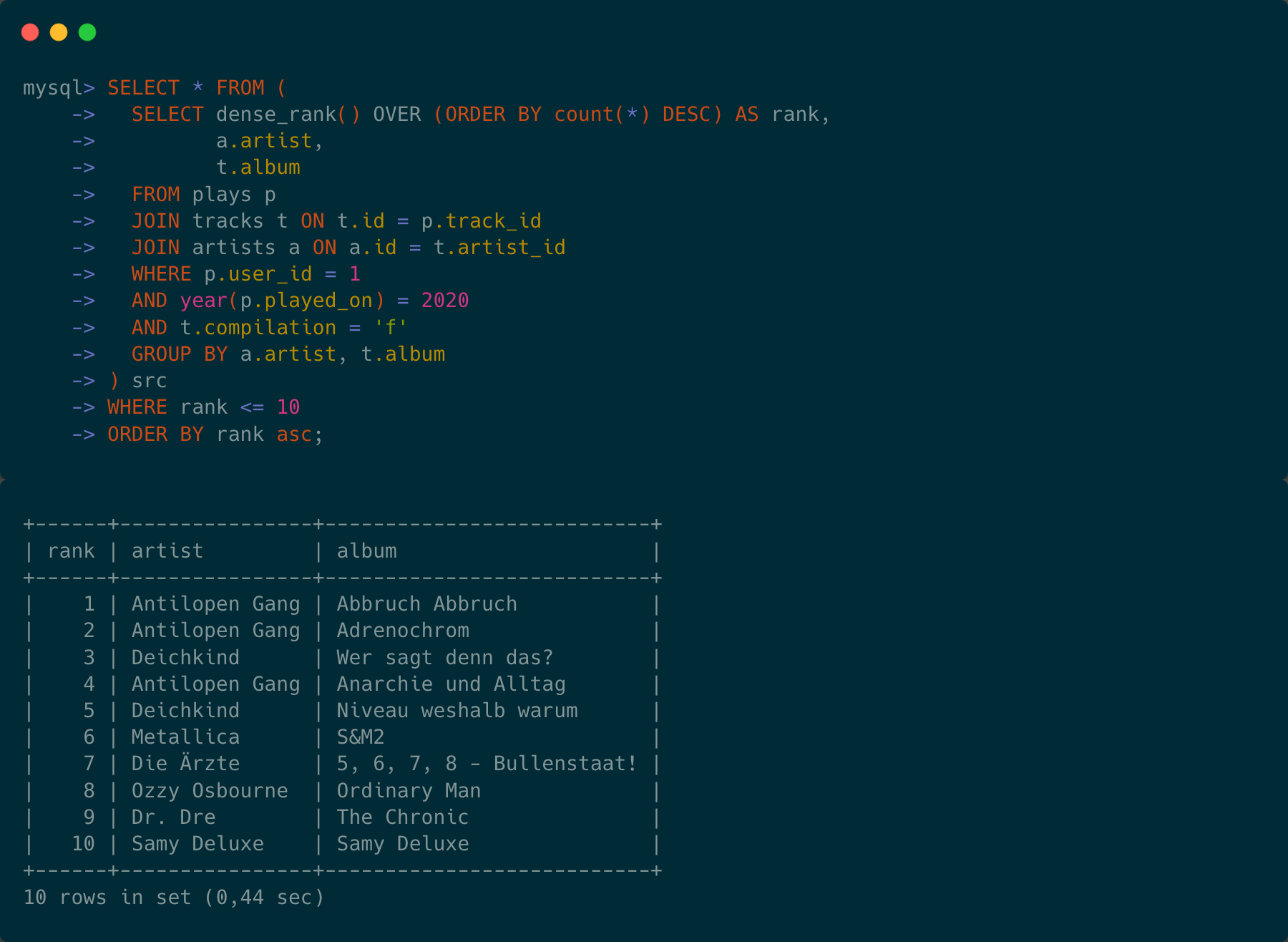
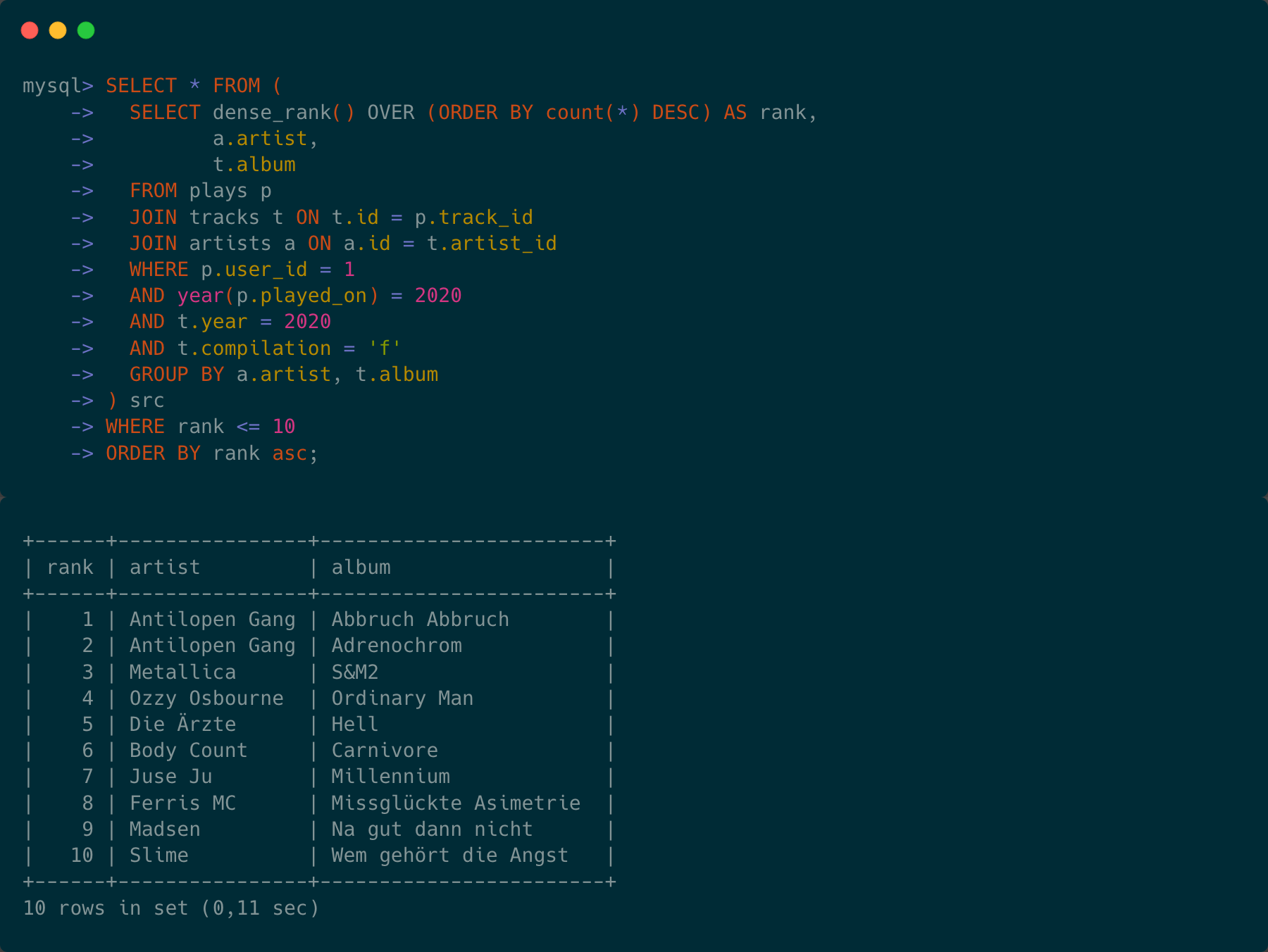
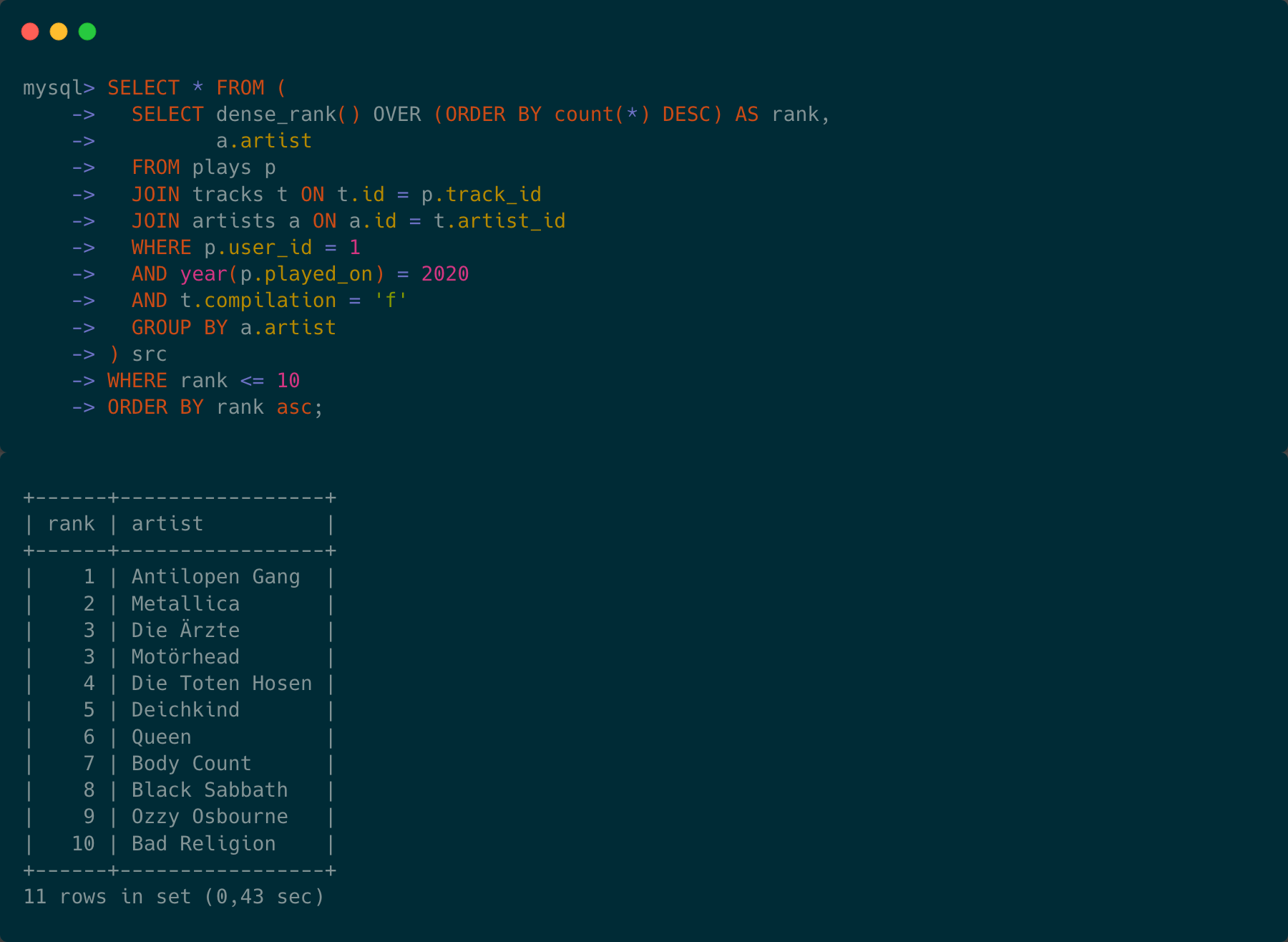
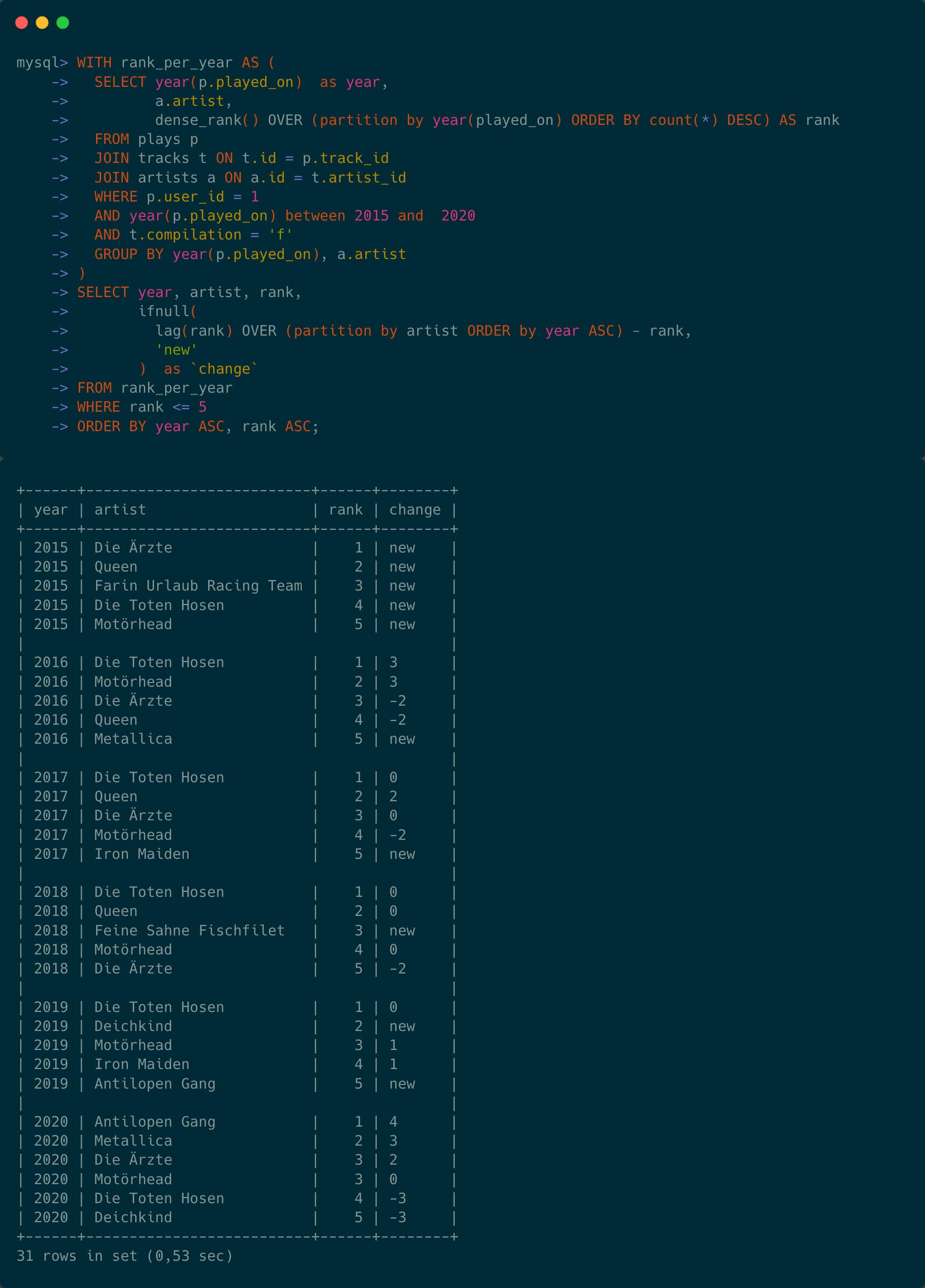
A couple of days ago I sent out this tweet here:
This tweet caused quite some reaction and with the following piece I want to clarify my train of thoughts behind it. First of all, let’s pick the components here and explain what they are.
The complete source code for all examples is on GitHub: michael-simons/native-story. Title image is from Alexander. Cheers, hugs and thank you to Gerrit, Michael and Gunnar for your reviews, proofreading and feedback.
GraalVM
GraalVM is a high-performance runtime that provides significant improvements in application performance and efficiency which is ideal for microservices. Quoted from the GraalVM website:
“GraalVM is a high-performance runtime that provides significant improvements in application performance and efficiency which is ideal for microservices. It is designed for applications written in Java, JavaScript, LLVM-based languages.”
One benefit of the GraalVM is a new just-in-time compilation mechanism, which makes many scenarios running on GraalVM faster than running on a comparable JDK. However, there is more. Also quoting from the above intro: “For existing Java applications, GraalVM can provide benefits by […] creating ahead-of-time compiled native images.”
SubstrateVM
The SubstrateVM is the part of GraalVM that is responsible for running the native image. The readme states:
(A native image) does not run on the Java VM, but includes necessary components like memory management and thread scheduling from a different virtual machine, called “Substrate VM”. Substrate VM is the name for the runtime components (like the deoptimizer, garbage collector, thread scheduling etc.). The resulting program has faster startup time and lower runtime memory overhead compared to a Java VM.
The GraalVM team has a couple of benchmarks showing the benefits from running microservices as native images.
Those numbers are impressing, no doubt, and they will have a positive effect for many applications.
I wrote my sentiment not as an author of applications, but as an author and contributor of database drivers supporting encrypted connections to servers as well as an object mapping framework that takes arbitrary domain objects (in form of whatever classes people can think of) and creates instances of those dynamically from database queries and vice versa.
This text is not an exhaustive take on the GraalVM and its fantastic tooling. It’s a collections of things I learned during making the Neo4j Java Driver, the Quarkus Neo4j extension, Spring Data Neo4j 6 and some GraalVM polyglot examples native image compatible.
Since my first ever encounter with GraalVM back in 2017 at JCrete, things have become rather easy for application developers. There is the native-image tool that takes classes or a whole jar containing a main class or the corresponding Maven plugin and produces a native executable.
There is a great getting started Install GraalVM which you can follow as an application developer step by step. Make sure you install the native-image tool, too.
Giving the following trivial program – which can be run as a single source file java trivial/src/main/java/ac/simons/native_story/trivial/Application.java Michael producing Hello, Michael –
package ac.simons.native_story.trivial;
public class Application {
public static void main(String... args) {
System.out.println("Hello, " + (args.length == 0 ? "User" : args[0]));
}
} |
package ac.simons.native_story.trivial;
public class Application {
public static void main(String... args) {
System.out.println("Hello, " + (args.length == 0 ? "User" : args[0]));
}
}
Compile this with first with javac and after that, run native-image like this:
javac trivial/src/main/java/ac/simons/native_story/trivial/Application.java
native-image -cp trivial/src/main/java ac.simons.native_story.trivial.Application app
It will produce some output like this
Build on Server(pid: 21148, port: 50583)
[ac.simons.native_story.trivial.application:21148] classlist: 71.34 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (cap): 1,663.79 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] setup: 1,850.67 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (clinit): 107.06 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (typeflow): 2,620.63 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (objects): 3,051.08 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (features): 83.23 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] analysis: 5,962.31 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] universe: 112.18 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (parse): 218.57 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (inline): 494.42 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (compile): 912.43 ms, 4.43 GB
[ac.simons.native_story.trivial.application:21148] compile: 1,828.57 ms, 4.43 GB
[ac.simons.native_story.trivial.application:21148] image: 465.08 ms, 4.43 GB
[ac.simons.native_story.trivial.application:21148] write: 135.90 ms, 4.43 GB
[ac.simons.native_story.trivial.application:21148] [total]: 10,465.92 ms, 4.43 GB |
Build on Server(pid: 21148, port: 50583)
[ac.simons.native_story.trivial.application:21148] classlist: 71.34 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (cap): 1,663.79 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] setup: 1,850.67 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (clinit): 107.06 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (typeflow): 2,620.63 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (objects): 3,051.08 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (features): 83.23 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] analysis: 5,962.31 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] universe: 112.18 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (parse): 218.57 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (inline): 494.42 ms, 4.55 GB
[ac.simons.native_story.trivial.application:21148] (compile): 912.43 ms, 4.43 GB
[ac.simons.native_story.trivial.application:21148] compile: 1,828.57 ms, 4.43 GB
[ac.simons.native_story.trivial.application:21148] image: 465.08 ms, 4.43 GB
[ac.simons.native_story.trivial.application:21148] write: 135.90 ms, 4.43 GB
[ac.simons.native_story.trivial.application:21148] [total]: 10,465.92 ms, 4.43 GB
and eventually you can run a native executable like this ./app Michael. Adding the corresponding Maven plugins to the project makes that part of the build. Pretty neat.
So far, so good and done? From this application, of course. But having framework needs is a bit more elaborated.
A fictive “framework”
Let’s take this simple “hello-world” application and turn it into something artificially complicated. Imagine we are writing a complex application, having some framework like traits. So, the “greeting” must be turned into an interface based service:
public interface Service {
String sayHelloTo(String name);
String getGreetingFromResource();
} |
public interface Service {
String sayHelloTo(String name);
String getGreetingFromResource();
}
Of course, we need a factory to get instances of that service
public class ServiceFactory {
public Service getService() {
Class<Service> aClass;
try {
aClass = (Class<Service>) Class.forName(ServiceImpl.class.getName());
return aClass.getConstructor().newInstance();
} catch (Exception e) {
throw new RuntimeException("¯\\_(ツ)_/¯", e);
}
}
} |
public class ServiceFactory {
public Service getService() {
Class<Service> aClass;
try {
aClass = (Class<Service>) Class.forName(ServiceImpl.class.getName());
return aClass.getConstructor().newInstance();
} catch (Exception e) {
throw new RuntimeException("¯\\_(ツ)_/¯", e);
}
}
}
The implementation of the service should look something like this
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UncheckedIOException;
import java.util.stream.Collectors;
public class ServiceImpl implements Service {
private final TimeService timeService = new TimeService();
@Override
public String sayHelloTo(String name) {
return "Hello " + name + " from ServiceImpl at " + timeService.getStartupTime();
}
@Override
public String getGreetingFromResource() {
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(this.getClass().getResourceAsStream("/content/greeting.txt")))) {
return reader.lines()
.collect(Collectors.joining(System.lineSeparator()));
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
} |
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UncheckedIOException;
import java.util.stream.Collectors;
public class ServiceImpl implements Service {
private final TimeService timeService = new TimeService();
@Override
public String sayHelloTo(String name) {
return "Hello " + name + " from ServiceImpl at " + timeService.getStartupTime();
}
@Override
public String getGreetingFromResource() {
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(this.getClass().getResourceAsStream("/content/greeting.txt")))) {
return reader.lines()
.collect(Collectors.joining(System.lineSeparator()));
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
}
That looks actually rather simple. As an added bonus, it includes a TimeService that returns the start of the application. That service is implemented in a super naive way:
import java.time.Instant;
public class TimeService {
private final static Instant STARTED_AT = Instant.now();
public Instant getStartupTime() {
return STARTED_AT;
}
} |
import java.time.Instant;
public class TimeService {
private final static Instant STARTED_AT = Instant.now();
public Instant getStartupTime() {
return STARTED_AT;
}
}
It’s problematic on its own, but that shall not be the point here. Last but not least, let’s blow up the application itself a bit:
import java.lang.reflect.Method;
public class Application {
public static void main(String... a) {
Service service = new ServiceFactory().getService();
System.out.println(service.sayHelloTo("GraalVM"));
System.out.println(invokeGreetingFromResource(service, "getGreetingFromResource"));
}
static String invokeGreetingFromResource(Service service, String theName) {
try {
Method method = Service.class.getMethod(theName);
return (String) method.invoke(service);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
} |
import java.lang.reflect.Method;
public class Application {
public static void main(String... a) {
Service service = new ServiceFactory().getService();
System.out.println(service.sayHelloTo("GraalVM"));
System.out.println(invokeGreetingFromResource(service, "getGreetingFromResource"));
}
static String invokeGreetingFromResource(Service service, String theName) {
try {
Method method = Service.class.getMethod(theName);
return (String) method.invoke(service);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
I tried to make up some examples that need to be addressed due to limitations of Graals ahead of time compilation described here.
What do we have?
- A factory producing an instance based on a dynamic class name (non compile time constant), the
ServiceFactory
- A dynamic method call (could be a field call or whatever through
java.lang.reflect in Application)
- A service that uses some resources (
getGreetingFromResource).
- Another service that uses a static field initialized during class initialization containing a sensible value dependent on the current time (
TimeService)
When I package this application as a jar file, containing a manifest entry pointing to the main class, I can run it like this:
java -jar only-on-jvm/target/only-on-jvm-1.0-SNAPSHOT.jar
Hello GraalVM from ServiceImpl at 2020-09-15T09:37:37.832141Z
Hello, from a resource. |
java -jar only-on-jvm/target/only-on-jvm-1.0-SNAPSHOT.jar
Hello GraalVM from ServiceImpl at 2020-09-15T09:37:37.832141Z
Hello, from a resource.
However, pointing native-image to it, now results in a couple of warnings
native-image -jar only-on-jvm/target/only-on-jvm-1.0-SNAPSHOT.jar
...
Warning: Reflection method java.lang.Class.forName invoked at ac.simons.native_story.ServiceFactory.getService(ServiceFactory.java:8)
Warning: Reflection method java.lang.Class.getMethod invoked at ac.simons.native_story.Application.invokeGreetingFromResource(Application.java:18)
Warning: Reflection method java.lang.Class.getConstructor invoked at ac.simons.native_story.ServiceFactory.getService(ServiceFactory.java:9)
Warning: Aborting stand-alone image build due to reflection use without configuration.
Warning: Use -H:+ReportExceptionStackTraces to print stacktrace of underlying exception
Build on Server(pid: 26437, port: 61293)
...
Warning: Image 'only-on-jvm-1.0-SNAPSHOT' is a fallback image that requires a JDK for execution (use --no-fallback to suppress fallback image generation and to print more detailed information why a fallback image was necessary). |
native-image -jar only-on-jvm/target/only-on-jvm-1.0-SNAPSHOT.jar
...
Warning: Reflection method java.lang.Class.forName invoked at ac.simons.native_story.ServiceFactory.getService(ServiceFactory.java:8)
Warning: Reflection method java.lang.Class.getMethod invoked at ac.simons.native_story.Application.invokeGreetingFromResource(Application.java:18)
Warning: Reflection method java.lang.Class.getConstructor invoked at ac.simons.native_story.ServiceFactory.getService(ServiceFactory.java:9)
Warning: Aborting stand-alone image build due to reflection use without configuration.
Warning: Use -H:+ReportExceptionStackTraces to print stacktrace of underlying exception
Build on Server(pid: 26437, port: 61293)
...
Warning: Image 'only-on-jvm-1.0-SNAPSHOT' is a fallback image that requires a JDK for execution (use --no-fallback to suppress fallback image generation and to print more detailed information why a fallback image was necessary).
A fallback image that requires a JDK means that the resulting image – however not being much smaller or larger than a non-fallback – requires the JDK to be present at runtime. If you remove the JDK from your path and try to execute it, it will greet you with:
./only-on-jvm-1.0-SNAPSHOT
Error: No bin/java and no environment variable JAVA_HOME
What tools are available to address the issues? Let’s first tackle the first two, both dynamic class loading and Java reflection. We have two options:
We can enumerate what classes need to be present in the native image and what methods as well and to which methods reflection based access should be available. Or we can substitute classes or methods when run on GraalVM.
Enumerating things present in the native image
The GraalVM analysis intercepts calls like the one to Class.forName and tries to reduce their arguments to a compile time constant. If this succeeds, the class in question is added to the image. The above example is contrived so that the analysis cannot do this. This is where the “reflection config” can come into place. The native-image tool takes -H:ReflectionConfigurationFiles as arguments which points to JSON files containing something like this:
[
{
"name" : "ac.simons.native_story.ServiceImpl",
"allPublicConstructors" : true
},
{
"name" : "ac.simons.native_story.Service",
"allPublicMethods" : true
}
] |
[
{
"name" : "ac.simons.native_story.ServiceImpl",
"allPublicConstructors" : true
},
{
"name" : "ac.simons.native_story.Service",
"allPublicMethods" : true
}
]
Here we declare that we want allow reflective access to all public constructors of ServiceImpl so that we can get an instance of it and allow access to all public methods of the services interface.
There are more options as described here.
One way to make native-image use that config is to pass it as
-H:ReflectionConfigurationFiles=/path/to/reflectconfig, but I prefer having one
native-image.properties in META-INF/native-image/GROUP_ID/ARTIFACT_ID which is picked up by the native-image tool.
That native-image.properties contains so far the following:
Args = -H:ReflectionConfigurationResources=${.}/reflection-config.json |
Args = -H:ReflectionConfigurationResources=${.}/reflection-config.json
Pointing to the above config.
This will compile the image just nicely. However, it will still fail with a NullPointerException: The greeting.txt resource has not been included in the image.
This can be fixed with a resources-config.json like this
{
"resources": [
{
"pattern": ".*greeting.txt$"
}
]
} |
{
"resources": [
{
"pattern": ".*greeting.txt$"
}
]
}
The appropriate stanza needs to be added to the image properties, so that we have now:
Args = -H:ReflectionConfigurationResources=${.}/reflection-config.json \
-H:ResourceConfigurationResources=${.}/resources-config.json |
Args = -H:ReflectionConfigurationResources=${.}/reflection-config.json \
-H:ResourceConfigurationResources=${.}/resources-config.json
Note The arguments for specifying configuration in form of some JSON “things” come in two options: As XXXConfigurationResources and XXXConfigurationFiles which I learned in this issue (which is great example of fantastic communication from an OSS project). The resources-form is for everything inside your artifact, the files-form is for external files. The wildcard ${.} resolves accordingly. All the options to specify can be retrieved with something like this: native-image --expert-options | grep Configuration
Now the image runs without errors:
./reflection-config-1.0-SNAPSHOT
Hello GraalVM from ServiceImpl at 2020-09-15T15:02:47.572800Z
Hello, from a resource. |
./reflection-config-1.0-SNAPSHOT
Hello GraalVM from ServiceImpl at 2020-09-15T15:02:47.572800Z
Hello, from a resource.
But does it run without bugs? Well not exactly. I wrote a bit more text, time went on and when I run it again, it prints the same date. Look back at the TimeService. It holds an instance of private final static Instant STARTED_AT = Instant.now();. It must be initialized before the time service is used.
I’m actually unsure why the native image tool considers the TimeService class as “safe” (described here) and choses to initialize it at build time (which also contradicts Runtime vs Build-Time Initialization stating “Since GraalVM 19.0 all class-initialization code (static initializers and static field initialization)”. At first I thought that happens as I “hide” the TimeServices usage behind my reflection based code, but I can reproduce it without it, too.
At the time of writing, I asked for this on the GraalVM slack and we see how it will be answered. Until then, I’m happy to have a somewhat contrived example. The TimeService must be of course initialized at runtime, it is not safe. This is done via --initialize-at-run-time arguments to the native image tool.
So now we have:
Args = -H:ReflectionConfigurationResources=${.}/reflection-config.json \
-H:ResourceConfigurationResources=${.}/resources-config.json \
--initialize-at-run-time=ac.simons.native_story.TimeService |
Args = -H:ReflectionConfigurationResources=${.}/reflection-config.json \
-H:ResourceConfigurationResources=${.}/resources-config.json \
--initialize-at-run-time=ac.simons.native_story.TimeService
And a correctly working, native binary.
Substitutions
Working on making the Neo4j driver natively compilable was much more effort. We used Netty underneath for SSL connections. A couple of things need to be enabled on the native image tool to get the groundworks running (like having those -H:EnableURLProtocols=http,https --enable-all-security-services -H:+JNI options which can be added in the same manner like we did above).
A couple of other things needed active substitutions.
With the “SVM” project the GraalVM provides a way to substitute whole classes or methods during the image build:
<dependency>
<groupId>org.graalvm.nativeimage</groupId>
<artifactId>svm</artifactId>
<version>${native-image-maven-plugin.version}</version>
<!-- Provided scope as it is only needed for compiling the SVM substitution classes -->
<scope>provided</scope>
</dependency> |
<dependency>
<groupId>org.graalvm.nativeimage</groupId>
<artifactId>svm</artifactId>
<version>${native-image-maven-plugin.version}</version>
<!-- Provided scope as it is only needed for compiling the SVM substitution classes -->
<scope>provided</scope>
</dependency>
Now we can provide them like this in a package private class like CustomSubstitutions.java hidden away.
import ac.simons.native_story.Service;
import ac.simons.native_story.ServiceImpl;
import com.oracle.svm.core.annotate.Substitute;
import com.oracle.svm.core.annotate.TargetClass;
@TargetClass(className = "ac.simons.native_story.ServiceFactory")
final class Target_ac_simons_native_story_ServiceFactory {
@Substitute
private Service getService() {
return new ServiceImpl();
}
}
@TargetClass(className = "ac.simons.native_story.Application")
final class Target_ac_simons_native_story_Application {
@Substitute
private static String invokeGreetingFromResource(Service service, String theName) {
return "#" + theName + " on " + service + " should have been called.";
}
}
class CustomSubstitutions {
} |
import ac.simons.native_story.Service;
import ac.simons.native_story.ServiceImpl;
import com.oracle.svm.core.annotate.Substitute;
import com.oracle.svm.core.annotate.TargetClass;
@TargetClass(className = "ac.simons.native_story.ServiceFactory")
final class Target_ac_simons_native_story_ServiceFactory {
@Substitute
private Service getService() {
return new ServiceImpl();
}
}
@TargetClass(className = "ac.simons.native_story.Application")
final class Target_ac_simons_native_story_Application {
@Substitute
private static String invokeGreetingFromResource(Service service, String theName) {
return "#" + theName + " on " + service + " should have been called.";
}
}
class CustomSubstitutions {
}
The names of the classes don’t matter, the target classes do of course.
With that, -H:ReflectionConfigurationResources=${.}/reflection-config.json can go away (in our case). You can do a lot of stuff in the substitutions. Have a look at what we do in Neo4j Java driver.
The tracing agent
Thanks to Gunnar I learned about GraalVMs Reflection tracing agent. It can discover most of things described above for you.
Running the only-on-jvm example from the beginning with the agent enabled, it generates the full configuration for us. For this to work, you must of course be running the OpenJDK version of the GraalVM already:
java --version
openjdk 11.0.7 2020-04-14
OpenJDK Runtime Environment GraalVM CE 20.1.0 (build 11.0.7+10-jvmci-20.1-b02)
OpenJDK 64-Bit Server VM GraalVM CE 20.1.0 (build 11.0.7+10-jvmci-20.1-b02, mixed mode, sharing)
java -agentlib:native-image-agent=config-output-dir=only-on-jvm/target/generated-config -jar only-on-jvm/target/only-on-jvm-1.0-SNAPSHOT.jar
Hello GraalVM from ServiceImpl at 2020-09-16T07:12:27.194185Z
Hello, from a resource. |
java --version
openjdk 11.0.7 2020-04-14
OpenJDK Runtime Environment GraalVM CE 20.1.0 (build 11.0.7+10-jvmci-20.1-b02)
OpenJDK 64-Bit Server VM GraalVM CE 20.1.0 (build 11.0.7+10-jvmci-20.1-b02, mixed mode, sharing)
java -agentlib:native-image-agent=config-output-dir=only-on-jvm/target/generated-config -jar only-on-jvm/target/only-on-jvm-1.0-SNAPSHOT.jar
Hello GraalVM from ServiceImpl at 2020-09-16T07:12:27.194185Z
Hello, from a resource.
The result looks like this:
dir only-on-jvm/target/generated-config
total 32
14417465 0 drwxr-xr-x 6 msimons staff 192 16 Sep 09:12 .
14396074 0 drwxr-xr-x 8 msimons staff 256 16 Sep 09:12 ..
14417471 8 -rw-r--r-- 1 msimons staff 278 16 Sep 09:12 jni-config.json
14417468 8 -rw-r--r-- 1 msimons staff 4 16 Sep 09:12 proxy-config.json
14417470 8 -rw-r--r-- 1 msimons staff 226 16 Sep 09:12 reflect-config.json
14417469 8 -rw-r--r-- 1 msimons staff 77 16 Sep 09:12 resource-config.json |
dir only-on-jvm/target/generated-config
total 32
14417465 0 drwxr-xr-x 6 msimons staff 192 16 Sep 09:12 .
14396074 0 drwxr-xr-x 8 msimons staff 256 16 Sep 09:12 ..
14417471 8 -rw-r--r-- 1 msimons staff 278 16 Sep 09:12 jni-config.json
14417468 8 -rw-r--r-- 1 msimons staff 4 16 Sep 09:12 proxy-config.json
14417470 8 -rw-r--r-- 1 msimons staff 226 16 Sep 09:12 reflect-config.json
14417469 8 -rw-r--r-- 1 msimons staff 77 16 Sep 09:12 resource-config.json
Looking into the reflect-config.json we find a less coarse version of what I used above:
[
{
"name":"ac.simons.native_story.Service",
"methods":[{"name":"getGreetingFromResource","parameterTypes":[] }]
},
{
"name":"ac.simons.native_story.ServiceImpl",
"methods":[{"name":"<init>","parameterTypes":[] }]
}
] |
[
{
"name":"ac.simons.native_story.Service",
"methods":[{"name":"getGreetingFromResource","parameterTypes":[] }]
},
{
"name":"ac.simons.native_story.ServiceImpl",
"methods":[{"name":"<init>","parameterTypes":[] }]
}
]
The configuration is in fact complete in my example, as none of the dynamic method calls depend on input. If input varies the method calls, the agent has ways of merging the generated config.
In anyway, the agent is a fantastic tool to get you up and running with a base configuration for your libraries native config.
Quintessence
Without much effort I can make up a framework or program that is not exactly a good fit for a native binary. Of course, those examples here are contrived but I am pretty sure a couple of things I did here are to be found in many many applications still written today.
Also, reflection is used a lot in frameworks like Spring-Core, Hibernate ORM and of course Neo4j-OGM and Spring Data. For DI related frameworks, reflections make it easy to create injectors and wire dependencies. Object mappers don’t have an idea of what people are gonna throw at them.
Some of the things can be solved very elegantly with compile-time processors and resolve annotations and injections into byte code. This is what Micronaut does for example. Or with prebuilt indexes for domain classes like the Hibernate extensions in Quarkus do.
Older frameworks like Spring that also integrate over a lot of other things don’t have that luxury right now.
Either way, the tooling on the framework sides is improving a lot. Quarkus has several annotations and config options that generates the appropriate parameters and things as described above and a nice extension mechanism I described here. Spring will provide similar things through the spring-graalvm-native project. For Spring Data Neo4j the hints will probably look similar to this. In the end: Those solutions will translate to what I described above eventually.
Also bear in mind that there’s more that needs configuration: I addressed only reflection and resources but not JNI or proxies. There are shims and actuators to make them work as well.
I think that all the tooling around GraalVM native images is great and well documented. However, as you can see in my contrived example, there can be some pitfalls, even with applications that may seem trivial. Just pointing the native-image command against your class or jar file is not enough. Your test scenarios for services running native must be rather strict. If they spot errors, there is a plethora of utilities to help you with edge cases.
If you want to have more information, I really like this talk given at Spring One 2020 by Sébastien Deleuze and Andy Clement called “The Path Towards Spring Boot Native Applications” and I think it has a couple of takeaways that are applicable to other frameworks and applications, too:
In the long run, the work we as library authors put into making this things possible will surely pay out. But the benefit that a native image provides for many scenarios is not a free lunch.
Filed in English posts
|