In the summer of 2018, I joined Neo4j. This seems odd at first, my “love” for relational databases and SQL is known. I didn’t have this slide in my jOOQ presentation for two years now without reason. But: Looking at the jOOQ and SQL talks from the perspective of early 2000s, they also seemed odd at first. Back then, I never thought doing that much with databases. That changed a lot.
My experience is that all the data your deal with usually has a much longer lifetime than any of your applications sitting on top of that. Knowing one or more database management systems is essential. Being able to query them even more: What Neo4j and relational databases have in common: A great, declarative way to tell them which data to return and not how to return them. In the case of a relational database, this is obviously SQL, which had quite the renaissance for a few years now. Neo4j’s lingua franca is Cypher.
I get to play with Cypher a lot, but in the end this is not what I am working on at Neo4j. My work is focused on our Object Graph Mapper, Neo4j-OGM and the related Spring Data Module, Spring Data Neo4j. We have written about that a bit on medium. Given my experience with Spring, Spring Data and Spring Boot, the role suddenly makes much more sense.
People who entered the IT-conference circus may know the merry-go-round (or should I say “trap”?) of “talks stress me out a lot” – “hey, this is great, just enter another CfP”. I fell for it again and proposed a talk with the above title to several conferences. Now, I have to come up with something.
Back in 2016, when I first held my talk Database centric applications with Spring Boot and jOOQ, I started to write my story down. Back then, it helped me a lot, so here we go again. Join me on my way from relational databases to databases with relations.
Content
- Part 1: What are we talking about here? (This post)
- Part 2: How to get data into Neo4j?
- Part 3: Accessing data stored in Neo4j on the JVM
- Part 4: Modeling a domain with Spring Data Neo4j and OGM
- Part 5: Running interesting queries with ease
What are we talking about here?
The domain will be music. I have been tracking my musical habits for more than 10 years now at my side project Daily Fratze and I enjoy looking back to what I listened like this months but 5 years ago.

The guy on the left, Edgar F. Codd invented the relational model back in the 1970s. A relation in this model doesn’t describe a relation like the one between two people or a musician associated with a band who released a new track. A relation in the relational model is a table itself. Foreign keys between tables ensure referential integrity, but cannot define relations themselves. I put down some thoughts a while back in this German deck. This is what a relation looks like in a relational database:
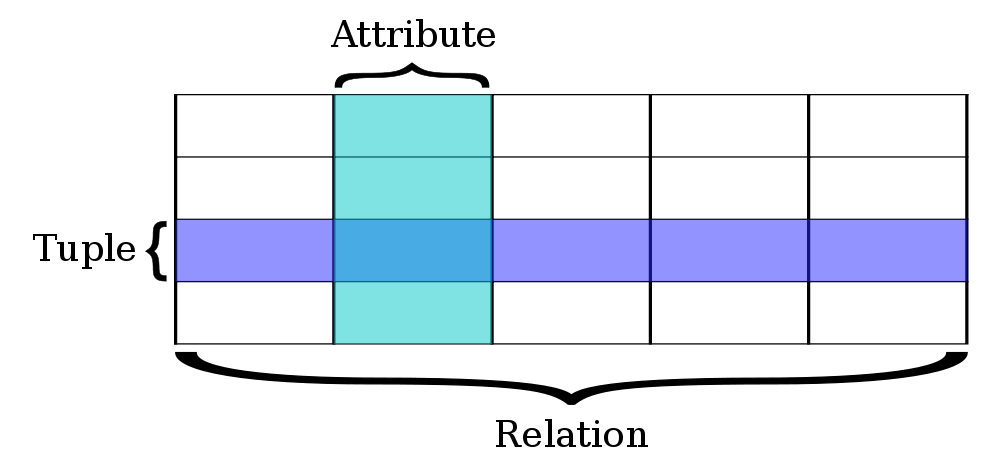
One kind of sport to do with relational databases is the process of normalizing data. There are several normal forms. Their goal is to keep a database redundancy free, for several reasons. Back in the 1970, disk space being one of them. First normal form (1NF): All attributes should be atomic. 2NF is 1NF plus no functional dependencies on parts of any candidate keys. That is: There must not be a pair of attributes appearing twice in a relation’s tuples. 3NF forbids transitive dependencies (“Nothing but the key, so help me Codd”) and it gets complicated from there on. I have to say though, that normalization up to 3NF is still relevant today in a relational systems, at least if you’re a friend of (strong) consistent data.
However, as my colleague Rik van Bruggen points out in his book “Learning Neo4j”, relational databases are quite anti-relational.
Why is this? Relations in NF can be queried in many, many ways. Each query send via SQL returns a new relation, what’s the problem? It depends. In a strictly analytical use case, there’s often not a problem. Recreating object hierarchies however, joining things back together, is. A handful of joins is not hard to understand, even without a tool, but self referential joins or a sheer, huge amount, is. It also gets increasingly hard on the database management system.
This is where graphs can come into play. Graphs are another mathematical concept, this time from Graph theory. Sometimes
people call a chart graph by coincident, but this is wrong. A graph is a set of objects with pairs of objects being related. In mathematical terms, those objects are vertices and the relations between them, edges. We call them nodes and relationships in the Neo4j database.
Neo4j is a Property Graph. A property graph adds labels and properties to both nodes and relationships:
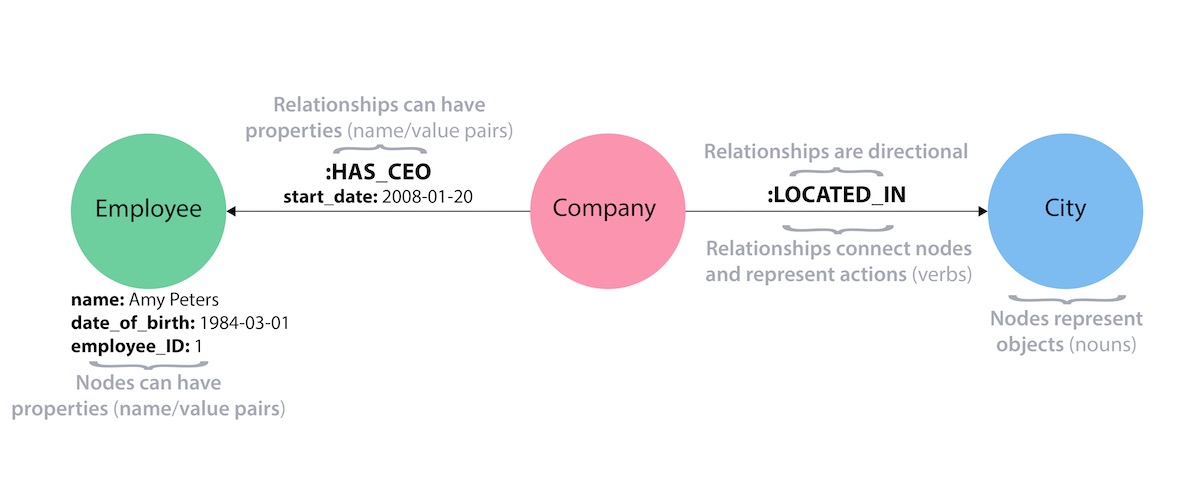
The above picture is from our excellent post What is a Graph Database?.
One takeaway from that post is: Neo4j is referred to as a native graph database because it efficiently implements the property graph model down to the storage level. Or in technical terms: Neo4j employs so called index-free adjacency, which is the most efficient means of processing data in a graph because connected nodes physically point to each other in the database. This obliterates the needs for complex joins, either directly or via intersection tables. One just can tell the database to retrieve all nodes connected to another node.
This is not only super nice for simple aggregations of things, but especially for many graph algorithms.
So what has this todo with my talk? My SQL talk was all about doing analytics. That is, retrieving data like in this image from a relational database with build-in analytic functions. Computing running totals, differences from previous windows and so on (read more here).
First of all I’m gonna analyze how to create a graph structure from the very same dataset I used in the SQL talk. There are different tools out there with different approaches. I’ve chosen a technique that resonated for various reasons with me. As I want to enrich the existing dataset, I’ll model a domain around it, with Java, putting Neo4j-OGM to use. I’ll show how Spring Data Neo4j helps me not having to deal with a lot of cruft. In the end, I’ll show that I can build my own music recommendation engine based on 10 years of tracking my musical habits by applying some of the queries and algorithms possible with Neo4j.
Next step: Loading data.
Pictures in this post: Codd and Table – Wikipedia, Property Graph – Neo4j, Featured image – Sarah Cervantes.




{kind=link}
{kind=link}
No comments yet
3 Trackbacks/Pingbacks
[…] @rotnroll666 Enter the password to view comments to this post. « From relational databases to databases with relations […]
[…] is the forth post in this series and I want to keep it short and […]
[…] >> From Relational Databases to Databases with Relations [info.michael-simons.eu] […]
Post a Comment