In the previous post I presented various ways how to get data into Neo4j. Now that you have a lot of connected data and it’s attributes, how to access, manipulate, add to them and delete them?
I’m working with and in the Spring ecosystem quite a while now and for me the straight answer is – without much surprises – just use the Spring Data Neo4j module if you work inside the Spring ecosystem. But to surprise of some, there’s more than just Spring there outside.
In this blog post I walk you through
- Using the Neoj4 Java-Driver directly
- Creating an application based on Micronaut, which went 1.0 GA these days, the Neo4j Java-Driver and Neo4-OGM
- A full blown Spring Boot application using Spring Data Neo4j
Before we jump right into some of the options you as an application developer have to access data inside Neo4j, we have to get a clear idea of some of the building blocks and moving parts involved. Let’s get started with those.
Building blocks and moving parts
Neo4j Java-Driver
The most important building block for access Neo4j on the JVM is possibly the Neo4j Java Driver. The Java driver is open source and is available on Github under the Apache License. This driver uses the binary “Bolt” protocol.
You can think of that driver as analogue to a JDBC driver that available for a relational database. Neo4j also offers drivers for different languages based on the Bolt protocol.
As with Java’s JDBC driver, there’s a bit of ceremony involved when working with this driver. First you have to acquire a driver instance and then open a session from which you can query the database:
try ( Driver driver = GraphDatabase.driver( uri, AuthTokens.basic( user, password ) ); Session session = driver.session() ) { List<String> artistNames = session .readTransaction(tx -> tx.run("MATCH (a:Artist) RETURN a", Map.of())) .list(record -> record.get("a").get("name").asString()); } |
With that code, one connects against the database and retrieves the names of all artists, I imported in my previous post. What I omitted here is the fact that the driver does connection pooling and one should not open and close it immediately. Instead, you would have to write some boiler plate code to handle this.
There are some important things to notice here: The code speaks of a driver. That is org.neo4j.driver.v1.Driver. The session is also from the same package: org.neo4j.driver.v1.Session. Those both are types from the driver itself. You have to know this things, because those terms will pop up later again. Neo4j-OGM, the object graph mapper, also speaks about drivers and session, but those are completely different things.
The Java driver has a nice type system (see The Cypher type system) and gets you quite far.
Most of the time however, people in the Java ecosystem prefer nominal typing over structural typing and want to map “all the things database” to objects of some kind. Let’s not get into bikeshedding here but just accept things as they are. Given a database model where a musical artist has multiple links to different wikipedia sites, represented like this (I omitted getter and setter for clarity):
public class WikipediaArticleEntity implements Comparable<WikipediaArticleEntity> { private Long id; private String site; private String title; private String url; public WikipediaArticleEntity(String site, String title, String url) { this.site = site; this.title = title; this.url = url; } } public class ArtistEntity { private String name; private String wikidataEntityId; private Set<WikipediaArticleEntity> wikipediaArticles = new TreeSet<>(); public ArtistEntity(String name, String wikidataEntityId, Set<WikipediaArticleEntity> wikipediaArticles) { this.name = name; this.wikidataEntityId = wikidataEntityId; this.wikipediaArticles = wikipediaArticles; } } |
To fill such a model directly by interacting purely with the driver, you’ll have to do something like this: A driver session get’s opened, than we write a query in Neo4j’s declarative graph query language called Cypher, execute and map all the returned records and nodes:
public List<ArtistEntity> findByName(String name) { try (Session s = driver.session()) { String statement = " MATCH (a:Artist) " + " WHERE a.name contains $name " + " WITH a " + " OPTIONAL MATCH (a) - [:HAS_LINK_TO] -> (w:WikipediaArticle)" + " RETURN a, collect(w) as wikipediaArticles"; return s.readTransaction(tx -> tx.run(statement, Collections.singletonMap("name", name))) .list(record -> { final Value artistNode = record.get("a"); final List<WikipediaArticleEntity> wikipediaArticles = record.get("wikipediaArticles") .asList(node -> new WikipediaArticleEntity( node.get("site").asString(), node.get("title").asString(), node.get("url").asString())); return new ArtistEntity( artistNode.get("name").asString(), artistNode.get("wikidataEntityId").asString(), new HashSet<>(wikipediaArticles) ); }); } } |
(This code is part of my example how to interact with Neo4j from a Micronaut application, find its source here and the whole application here.)
While this works, it’s quite an effort: For a simple thing (one root aggregate, the artist, with some attributes), a query that is not that simple anymore and a lot of manual mapping. The query makes good use of a standardized multiset (the collect-statement), to avoid having n+1 queries or deduplication of things on the client site, but all this mapping is kinda annoying for a simple READ operation.
Enter
Neo4j-OGM
Neo4j-OGM stands for Object-Graph-Mapper. It’s on the same level of abstraction as JPA/Hibernate are for relational databases. There’s extensive documentation: Neo4j-OGM – An Object Graph Mapping Library for Neo4j. An OGM maps nodes and relationships in the graph to objects and references in a domain model. Object instances are mapped to nodes while object references are mapped using relationships, or serialized to properties. JVM primitives are mapped to node or relationship properties.
Given the example from above, we only have to add a handful of simple annotations to make our domain usable with Neo4j-OGM:
@NodeEntity("WikipediaArticle") public class WikipediaArticleEntity implements Comparable<WikipediaArticleEntity> { @Id @GeneratedValue private Long id; private String site; private String title; private String url; WikipediaArticleEntity() { } public WikipediaArticleEntity(String site, String title, String url) { this.site = site; this.title = title; this.url = url; } } @NodeEntity("Artist") public class ArtistEntity { @Id @GeneratedValue private Long id; private String name; private String wikidataEntityId; @Relationship("HAS_LINK_TO") private Set<WikipediaArticleEntity> wikipediaArticles = new TreeSet<>(); ArtistEntity() { } public ArtistEntity(String name, String wikidataEntityId, Set<WikipediaArticleEntity> wikipediaArticles) { this.name = name; this.wikidataEntityId = wikidataEntityId; this.wikipediaArticles = wikipediaArticles; } } |
Notice @NodeEntity on the classes, @Relationship on the attribute wikipediaArticles of the ArtistEntity-class and some technical details, mainly @Id @GeneratedValue, needed to map Neo4j's internal, technical ids to instances of the classes and vice-versa.
@NodeEntity and @Relationship are used not only to mark the classes and attributes as something to store in the graph, but also to specify labels to be used for the nodes and names for the relationship.
The whole query than folds together into something like this:
public Iterable<ArtistEntity> findByName(String name) { return this.session .loadAll(ArtistEntity.class, new Filter("name", ComparisonOperator.CONTAINING, name), 1); } |
Quite a different, right? Dealing with the driver, the driver's session and Cypher has been abstracted away. Take note that the above session attribute is not a Driver's session, but OGM's session. This is a bit confusing when you start using those things.
Again, this code is part of my example how to interact with Neo4j from a Micronaut application. The complete source of the above is here and the whole application here.
To be fair, Neo4j-OGM needs to be configured as well. This is done in it's simplest form with a drivers instance and a list of packages that contains domain entities as described above, for example like this:
public SessionFactory createSessionFactory(Driver driver) { return new org.neo4j.ogm.session.SessionFactory( new BoltDriver(driver), "ac.simons.music.micronaut.domain"); } |
The driver instance in the example above is instantiated by Micronaut. With Micronaut's configuration support, it would have been manually configured as in the very first example.
In a Spring Boot application, Spring Boot takes care of the driver and Spring Data Neo4j creates the OGM session and deals with transactions, among other things:
Spring Data Neo4j
Let's start with quoting Spring Data:
Spring Data’s mission is to provide a familiar and consistent, Spring-based programming model for data access while still retaining the special traits of the underlying data store. It makes it easy to use data access technologies, relational and non-relational databases, map-reduce frameworks, and cloud-based data services.
That goes so far, that Craig Walls is fairly correct when he says, that many stores "are mostly the same from a Spring Data perspective":
It’d be tricky to cover ALL NoSQL options and since they’re mostly the same from a Spring Data perspective, I focused on a couple that I could also cover reactive with.
— Craig Walls (@habuma) October 27, 2018
Spring Data Neo4j has some specialities, but on a superficial level, the above statement is correct.
Spring Data depends on the Spring Framework and given that, it's kinda hard to get it to work in environments other than Spring. If you're however using Spring Framework already, I wouldn't think twice to add Spring Data to the mix, regardless whether I have to deal with a relational database or Neo4j.
Given the entity ArtistEntity above, one can just declare a repository as this:
interface ArtistRepository extends Neo4jRepository<ArtistEntity, Long> { List<ArtistEntity> findByNameContaining(String name); } |
There is no need to add an implementation for that interface, this is done by Spring Data. Spring Data also wires up a Neo4j-OGM session that is aware of Spring transactions.
From an application developers point you don't have to deal with mapping, opening and closing sessions and transactions any longer, but only with one single "repository" as abstraction over a set of given entities.
Please be aware that the idea behind Spring Data and its repository concept is not having a repository for each entity there is, but only for the root aggregates. To quote Jens Schauder: "Repositories persist and load aggregates. An aggregate is a cluster of objects that form a unit, which should always be consistent. Also, it should always get persisted (and loaded) together. It has a single object, called the aggregate root, which is the only thing allowed to touch or reference the internals of the aggregate." (see Spring Data JDBC, References, and Aggregates).
In my "music" example, I deal with albums released in a given year. The release year is an integral part of the album and it would be weird having an additional repository for it.
So what are the specialities of Spring Data Neo4j? First of all, in the pure Neo4-OGM example you might have noticed the single, lone "1". That specifies the fetch depth in which entities should be loaded. Depending on how entities are modeled, you could ran in the problem, that you fetch your whole graph with hone single query. Specifying the depth means specifying how deep relationships should be fetch. The repository method can be declared analog:
interface ArtistRepository extends Neo4jRepository<ArtistEntity, Long> { List<ArtistEntity> findByNameContaining(String name, @Depth int depth); } |
People familiar with Spring Data know that derive query method like the findByNameContaining can be much more complicated. You could even write down
interface ArtistRepository extends Neo4jRepository<ArtistEntity, Long> { List<ArtistEntity> findByNameContainingOrWikipediaArticlesTitleIs(String name, String title, @Depth int depth); } |
and so on. I have seen some interesting finder methods here and there. While this is technically possible, I would recommend using the @Query annotation on the method name, write down the query myself and chose a method name that corresponds to the business.
Different abstraction levels
At this point it should be clear, that Neo4j Java-Driver, Neo4j-OGM and Spring Data act on different abstraction levels:
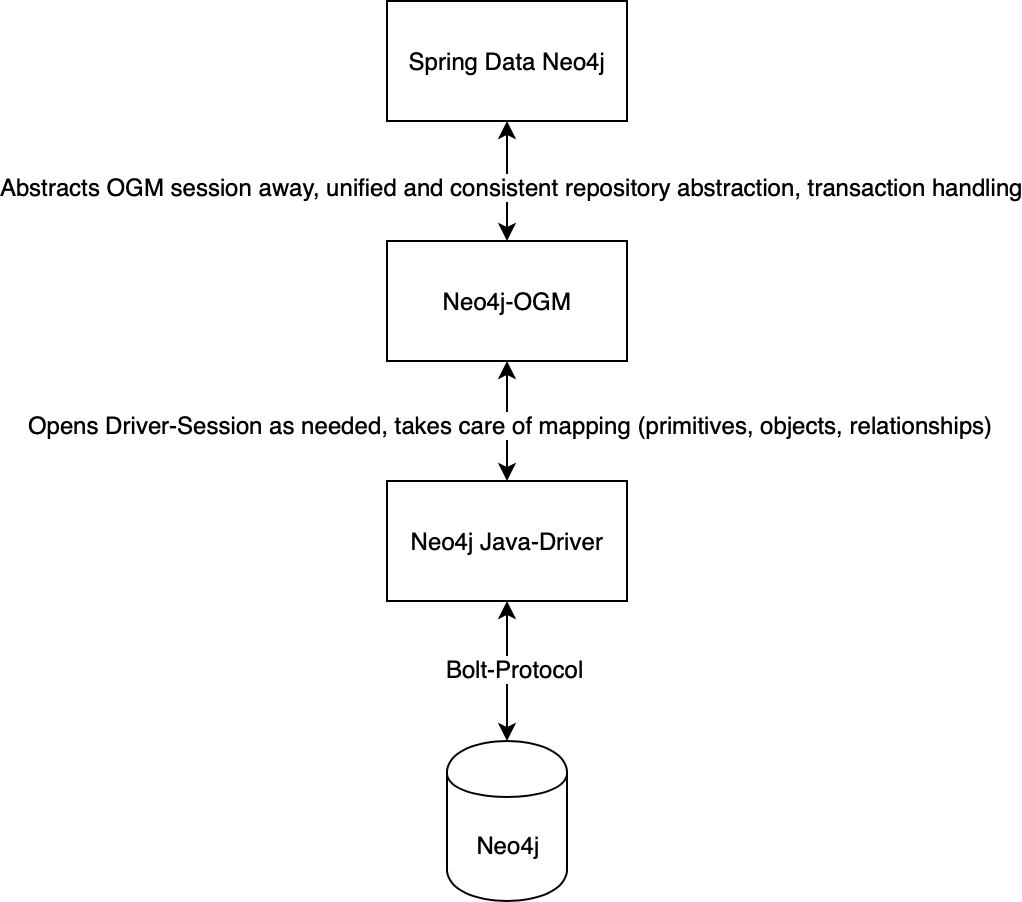
In your application, you have to decide which level of abstraction you need. You can come along way with direct interaction with the driver, especially for all kind of queries that facilitates your database for more than simple CRUD operations. However, I don't think that you want to deal with all the cruft of CRUD yourself throughout your application.
When to use what?
All three abstractions can execute all kind of Cypher queries. If you want to deal with result sets and records yourself and don't mind mapping stuff as you go along, use the Java driver. It has the least overhead. Not mapping stuff to fixed objects has the advantage that you can freely traverse relationships in your queries and use the results as needed.
As soon as you want to map nodes with the same labels and their relationship to other nodes more often than not, you should consider Neo4j-OGM. It takes away the "boring" mapping code from you and helps you to concentrate on your domain. Also, Neo4j-OGM is not tied to Spring. I didn't write application outside the Spring ecosystem for quite a while now. For this post, I needed an example where I don't have Spring, so I came up with the Micronaut demo, that uses both plain Java-Driver access and OGM access. Depending on what you want to achieve, you can combine both approaches: Mapping the boring stuff with Neo4j-OGM, handling "special" results yourself.
If you're writing an application in the Spring-Eco-System and decided for OGM, please also add Spring Data Neo4j to the mix. While it doesn't put any further abstraction layer on the mapping itself and thus is not slowing things down, it takes away the burden dealing with the session and transaction from you.
I do firmly believe that Spring Data Neo4j is the most flexible solution.
- Start with a simple repository, relying on the CRUD methods
- If necessary, declare your queries with
@Query - To differentiate between write and read models, execute writes through mapped
@NodeEntitiesand reads through read-only@QueryResults - Write a custom repository extension and interact directly with the Neo4j-OGM or Neo4j Java-Driver session
d
To complete this post, I'll show you option 2 and 3. Given my AlbumEntity, TrackEntity and a AlbumRepository.
First of all I want a query that retrieves all the albums containing one specific track. That is pretty easy to write in Cypher:
interface AlbumRepository extends Neo4jRepository<AlbumEntity, Long> { @Query(value = " MATCH (album:Album) - [:CONTAINS] -> (track:Track)" + " MATCH p=(album) - [*1] - ()" + " WHERE id(track) = $trackId" + " AND ALL(relationship IN relationships(p) WHERE type(relationship) <> 'CONTAINS')" + " RETURN p" ) List<AlbumEntity> findAllByTrack(Long trackId); } |
By declaring this additional method on the repository, I know have mapped a simple Cypher query that does complex thinks (Here match all albums that contain a specific track and all the relationships of that album and return that all apart from the other tracks) to my entity. I benefit from SDNs mapping and have all the queries in one place.
In my domain, I didn't model the track as part of the album. Those tracks should be explicitly read and not all the time. I therefore added an additional class, called AlbumTrack. Again, accessors omitted for brevity:
@QueryResult public class AlbumTrack { private Long id; private String name; private Long discNumber; private Long trackNumber; } |
Notice the @QueryResult annotation. This is special to Spring Data Neo4j. It marks this as a class that is instantiated from arbitrary query result but doesn't have a lifecycle. It then can be used as in a declarative query method, similar to the first one:
interface AlbumRepository extends Neo4jRepository<AlbumEntity, Long> { @Query(value = " MATCH (album:Album) - [c:CONTAINS] -> (track:Track) WHERE id(album) = $albumId" + " RETURN id(track) AS id, track.name AS name, c.discNumber AS discNumber, c.trackNumber AS trackNumber" + " ORDER BY c.discNumber ASC, c.trackNumber ASC" ) List<AlbumTrack> findAllAlbumTracks(Long albumId); } |
while this query is indeed much simpler as the first one, it's important to be able to do such things for designing an application that performs well. Think about it: Is it really necessary to have all the relations to all other possible nodes at hands all the time?
In the end, you might have guess it: There are no silver bullets. There are situations where an approach close to the database is more appropriate than another, sometimes a higher abstraction level is better. Whatever you chose, try not be to dogmatic.
All the examples are part of my bootiful music project, more specifically, the "knowledge" submodule. With the building blocks described here, you can develop an web application that is used for reading and writing data.
The example application uses a simple, server side rendered approach for the frontend, but Spring Data Neo4j plays well with Spring Data Rest and that makes many different approaches possible.
In the next installment of this series, we have a look at the concrete domain modeling with Spring Data Neo4j.




3 comments
You missed one of the most dynamic and flexible implementation, http://gorm.grails.org/6.1.x/neo4j/manual/
Thanks, Amad. I know GORM and I like it a lot.
Is the relational version still based on JPA?
Thank you for the post. It is very helpful.
Is it possible to use Spring Data for Neo4J within Micronaut, especially with the release of ver 2?
2 Trackbacks/Pingbacks
[…] >> No Silver Bullets Here: Accessing Data Stored in Neo4j on the JVM [info.michael-simons.eu] […]
[…] Michael Simons latest blog post he explores the different options for accessing, manipulating, adding and deleting data from Neo4j […]
Post a Comment