“Oh please no, Michael, not Sport content here”… Well, sorry, it’s my blog and right now I don’t have a much better place for it. Bear with me, though, there will be some cool database querying later on.
In late 2024 I stumbled upon No Rest for the Wicked 2025 and the idea is simple, even though the page describes it a bit complicated. The challenge is as follows:
Throughout February, do
- Do 24 runs in total
- Run once each hour of the day
- Run once on each weekday
- Each run (or walk / hike) must be at least 5km and at least 45 minutes
- A break of at least 90 minutes between each activity
That sounds like “fun”, let’s go:

There’s a race result event that tracks the progress and we come to that later. I was in the top twenty at the time of writing, with one activity to go and finished eleventh.
The challenge was quite an emotional ride for me between “oh my gosh what did I sign up for?”, “I never manager” etc. My favorite hours of the day for running is actually anything between 6 and 10am. Afternoon is ok, evenings I really dislike, especially after long working hours sitting. I have a really odd way of putting my feet down while sitting, so in the evening my ankles are always kinda busted. Night running? I never tried. As a matter of fact, I try to avoid activities with a high heart rate in the evenings.
So there was a lot going on outside of my comfort zone and I am very content that I did this:
- I felt good enough to go out in the middle of the freaking nights several times for running
- Running in the night was a lot more satisfying than walking, the latter just to boring alone and I didn’t want to put on headphones
- The silence was so nice, and so was the starry nights, quite unique, deeply satisfying experience
- Prior to getting up and out it’s tough, doing it is uplifting then
- One is capable of many things you never thought you are
- Happy that I live in a place that I can go out every time without having to be afraid of things
Honestly, at the end of 2 weeks I felt less depressed and down than usual in February. The last 3 years I travelled for a week to the Canaries to get some sun and cycling in, which I couldn’t do this year for personal reasons. This challenge was a great antidote.

So what does running here have to do with running database queries? Remember that Race result event above? I wanted to have an proper overview myself, without manual work and I created this:
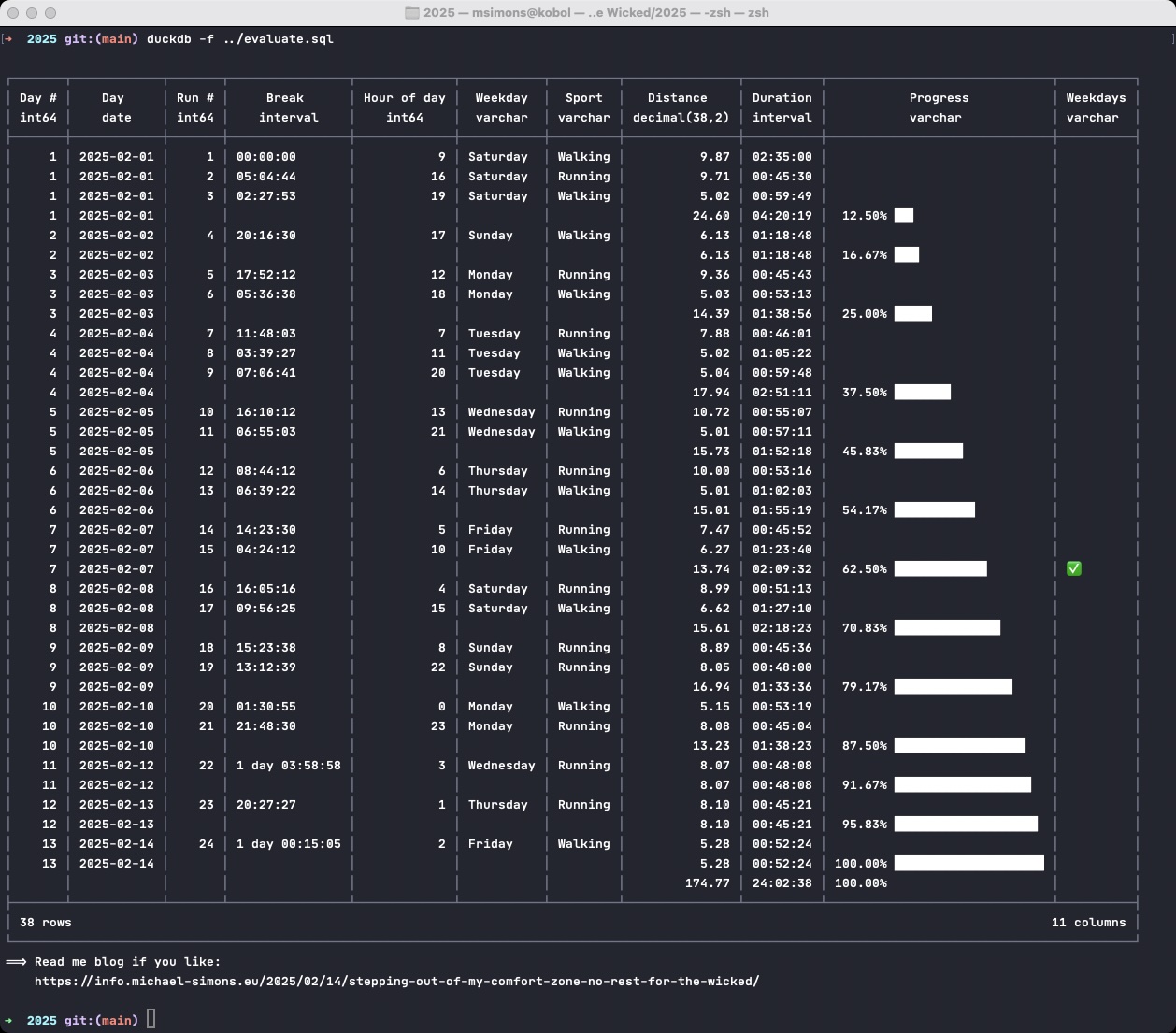
Looking at those number, would I do things differently? Yeah, I would probably not pushback the wee small hours between midnight and 3am to the end, but do them in the middle in two nights, in contrast spreading them over several days. I wasn’t sure if I would push through the challenge and my reasoning was that I didn’t want to fell for sunken costs. Anyhow, how did I create the above report? I went to connect.garmin.com, pulled down my activities as CSV for the past weeks, fired up DuckDB and ran that query:
WITH src AS ( SELECT DISTINCT ON (Datum, Titel) *, EXTRACT('hour' FROM Zeit)*60*60 + EXTRACT('minute' FROM Zeit)*60 + EXTRACT('second' FROM Zeit) AS Duration FROM read_csv('*.csv', union_by_name=TRUE, filename=FALSE) WHERE Titel LIKE 'NRFTW%' ), activities AS ( SELECT "Day #" : dense_rank() OVER (ORDER BY Datum::DATE), "Day" : Datum::DATE, "Run #" : ROW_NUMBER() OVER (), "Break" : age(Datum, COALESCE(date_add(lag(Datum) OVER starts, INTERVAL (lag(Duration) OVER starts) SECOND), Datum))::VARCHAR, "Hour of day": HOUR(Datum), "Weekday" : dayname(Datum), "Sport" : CASE Aktivitätstyp WHEN 'Gehen' THEN 'Walking' WHEN 'Laufen' THEN 'Running' ELSE Aktivitätstyp END, "Distance" : REPLACE(Distanz, ',', '.')::NUMERIC, "Duration" : EXTRACT('hour' FROM Zeit)*60*60 + EXTRACT('minute' FROM Zeit)*60 + EXTRACT('second' FROM Zeit), "Progress" : 100/24, FROM src WINDOW starts AS (ORDER BY Datum) ), sums AS ( SELECT * REPLACE( round(SUM(Distance), 2) AS Distance, to_seconds(SUM(Duration)) AS Duration, SUM(Progress) OVER dates AS Progress ), "p_weekdays" : COUNT(DISTINCT Weekday) OVER (ORDER BY DAY GROUPS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), "Weekdays" : COUNT(DISTINCT Weekday) OVER dates FROM activities GROUP BY GROUPING SETS (("Day #", "Run #", DAY, "Hour of day", Progress, Weekday, Break, Sport), ("Day #", DAY), ()) WINDOW dates AS (ORDER BY DAY) ) SELECT * EXCLUDE(p_weekdays) REPLACE ( Break::INTERVAL AS Break, CASE WHEN "Hour of day" IS NULL AND p_weekdays <> 7 AND Weekdays = 7 THEN '✅' END AS Weekdays, CASE WHEN DAY IS NULL THEN lpad(printf('%.2f%%', Progress), 7, ' ') WHEN "Hour of day" IS NULL THEN lpad(printf('%.2f%%', Progress), 7, ' ') || ' ' || bar(Progress, 0, 100, 20) END AS Progress ) FROM sums ORDER BY DAY, "Hour of day" NULLS LAST; |
It’s so funny how much value one can get out of basically three columns alone. I am basically working only on the start date, the duration and the distance. Everything else are derived values. Things to note: The progress per day and not per run (the latter would always be 1/24 of course), the checkbox when I hit the weekdays and the summary of distance and duration per day and overall. The nice formatting of the break time is a sweet bonus (using the age function). The DuckDB team just released 1.2.0 and put out a couple of blog posts that I really dig and I was able to utilize in my script:
- Vertical Stacking as the Relational Model Intended: UNION ALL BY NAME Great blog, great feature. Used it to union all the CSV files (they have had different columns, because some of them included cycling watts, some didn’t. See
FROM read_csv('*.csv', union_by_name=True, filename=False)in the query) - Catching up with Windowing Again, great content and I am a bit jealous because I think it’s more complete than the explanation in our book. I used the
GROUPSframing to figure out when I hit all the weekdays - Announcing DuckDB 1.2.0 New features in 1.2.0. I am mostly using the alternative projection syntax “X: U” compared to “U AS X” in the inner projection. It just reads better with long expressions.
Apart from that the query demonstrates again the power of window functions computing for example the break between activities as well as the day and activity numbers. It also makes extensive use of the addition to asterisk expression EXCLUDE and REPLACE avoiding juggling all the columns all over again. Also, take note of the GROUP BY with GROUPING SETS, which is the longer form of a GROUP BY ROLLUP that gives you control over the sets. Last bit is the sweet DISTINCT ON. I could just add more csv files, and this deduplicates not on all columns, but only on date and title.
This is what I like running: Challenges and algorithms locally, on my personal data. Those small and “crazy” challenges are so much nicer than the super commercialised side of running you find with the 6 star marathons or super halves. And the same thing applies to reports as the one I created here for myself–and through FLOSS and actually sharing how things are done–for others, too. For me being able to do this locally without any big vendor analytics is empowering and brings back a lot of joy that is missing today in many settings.
Challenge accepted and put to bed with walking and running roughly 175km in 24 hours total.





No comments yet
Post a Comment