These days my computer work is mostly concerned with all things Neo4j. Being it Spring Data Neo4j, the Cypher DSL, our integration with other frameworks and tooling or general internal things, among them being part of the Cypher language group.
In contrast to a couple of years, I don’t spent that much time around a computer in non-working hours anymore. My sleep got way better and I feel in general better. For reference, see the slides of a talk I wanted to give in 2020.
And I have to be honest: I feel distanced and tired of a couple of things I used to enjoy more a while back.
Last week however Hendrik Schreiber published japlscript and a collection of derived work: Java libraries that allow scripting of Apple applications on OS X and macOS.
As it happens, I have – as part of DailyFratze.de – a service that receives everything I play on iTunes and logs it. I have been doing this since 2005. The data accumulated with that service lead to several variations of this article and talk about database centric applications with Spring Boot and jOOQ. Here is the latest English version of it (in the speaker deck are more variations).
The sources behind that talk are in my repository bootiful-database. The repo started of with an Oracle database which I eventually replaced with Postgres. In both databases I can use modern SQL, for example window functions, all kinds of analytics, common table expressions and so on.
The actual live data is still in Daily Fratze. What that is? See DailyFratze: Ein tägliches Foto Projekt oder wie es zu “Macht was mit SQL und Spring” kam. However, there’s a caveat: The database of the service has been an older MySQL version for way too long. While it has charts like this visible to my users:
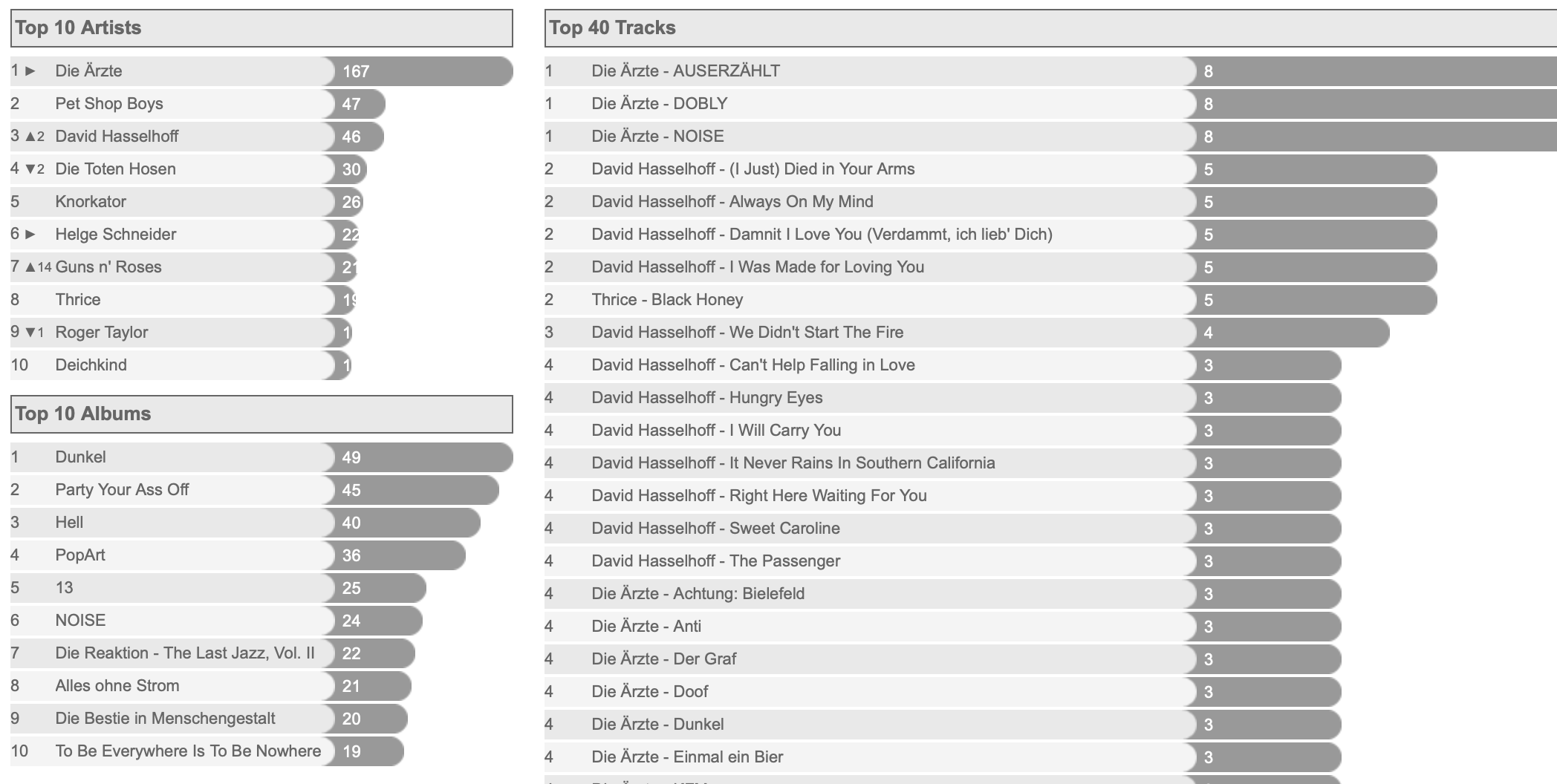
the queries are not as nice as the one in the talks.
When I wrote this post at the end of 2020, I had a look at MariaDB 10.5. It was super easy to import my old MySQL data from 5.6 into it and to my positive surprise, all SQL features I used from the talk could be applied.
So last week, the first step of building something new was migrating from MySQL 5.6 to MariaDB latest and to my positive (and big) surprise again: It was a walk in the park. Basically replacing repositories and updating the mysql-server package and accepting the new implementation. Hardly any downtime, even the old JDBC connector I use here and there can be reused. That’s developer friendly. My daily picture project just keeps running as is.
Now what?
- Scrobbling with Hendriks Library. Ideally in a modular way, having separate sources and sinks and an orchestrating application. It basically screams Java modules.
- Finally put the queries and stuff I talked so often about to a live application
I created scobbles4j. The idea is to have model represented in both SQL and Java records, a client module and a fresh server.
My goal is to keep the client dependency free (apart the modules integrating with Apple programs) and later use the fantastic JDK11+ HTTP Client. For the server I picked Quarkus. Why? It has been a breath of fresh air since 2019, a really pleasant to work with project and community. I was able to contribute several things Neo4j to it (and they even sent my shirts for that, how awesome!), but I never had the chance to really use it.
Java modules
Once you get the idea of modules, they help a lot on the scale of libraries and small applications like the one I want to build to keep things organized. Have a look at the sources api. It’s main export is this and implementations like the one for Apple Music can provide it like that. You see in the last linke, that the package scrobbles4j.client.sources.apple.music is not exported, so the service implementation just can stay public and is still not accessible. Neat. The client to this services need to know only the APIs: requiring service apis and loading them.
Thing you can explorer: How I added a “bundle” project, combining launcher and all sources and sinks and using jlink to create a custom runtime image.
Testing in a modular world is still sadly problematic. Maven / Surefire will stuff everything in test on the module path, IDEA on the class path. The later is easier, the former next to impossible without patching the module path (if you don’t want to have JUnit and friends in your main dependencies). Why? There’s only one module-info.java per artifact. As main and test sources are eventually combined, having an open module in test is forbidden.
There are a couple of posts like this, but tbh, I wasn’t able to make this fly. Eventually, I just opened my module explicitly in the surefire setup, which works for me with pure Maven and IDEs. Probably another approach like having explicit test modules is the way but this I find overkill for white box testing (aka plain unit tests).
Quarkus
One fact that is maybe not immediate obvious: Quarkus projects don’t have a default parent pom. They require you to import their dependency management and configure a custom Maven plugin. Nothing hard, see for yourself yourself. You probably won’t even notice it when create a new project at code.quarkus.io. However, it really helps you in a multi-module setup such as scrobbles4j. Much easier than one module wanting to have a separate parent.
I went the imperative way. Mainly I want to use Flyway for database migrations without additional fuzz. As I wanted to focus on queries and the results and also because I like it: Server side rendering it is. Here I picked Qute.
And about that SQL: To jOOQ or not to jOOQ? Well: I have only a hand full of queries, nothing to dynamic and I just want to have some fun and keep it simple. So no jOOQ, no building this time. And also, JDK 17 text blocks. I love them.
What about executing that SQL? If I had chosen the reactive way, I could have used the Quarkus reactive client. I haven’t. But nobody in their right mind will work with JDBC directly. Hmm… Jdbi to the rescue, the core module alone. I didn’t want mapping. In the Spring world, I would have picked JDBCTemplate. Also:
Of course 🙂
And I do still like you, dear jOOQ. No worries.
— Michael Simons (@rotnroll666) October 1, 2021
Deploying with fun
One good decision in the Quarkus world is that they don’t create fat jars by default, but a runnable jar in a file structure that feels like a fat jar. Those jars had their time and they had been necessary and they solved issues. This solution that you just can rsync somewhere in seconds, the quick restart times makes it feel like you’re editing PHP files again.
I was only half joking here:
Sure, sharing a database between two application is often a bad idea.
But, what if, one is a read only application? Why not just create a separate schema and do a create view v_xy from source.xy and have a nice day. pic.twitter.com/5DgQJ0rCiO
— Michael Simons (@rotnroll666) October 1, 2021
It is actually what I am doing: I created the application in such a way that it is runnable on a fresh scheme and usable by other people too. But I configured flyway in such a way that it will baseline an existing scheme and hold back any version up to a given one (see application.properties) and I can use the app with my original scheme.
However, I am not stupid. I am not gonna share the schema between to applications directly. I did create another database user with read-rights only (apart for Flyways schema history) and a dedicated schema and just created views in that schema for the original tables in the other one. The views do some prepping as well and are basically an API contract. Jordi here states:
This sounds a lot like a way to implement CQRS. One "app" stores, the other one just views the state.
Anyway, the boundaries between "apps" are so fuzzy that make me shiver.— ᴊᴏʀᴅɪ ꜱᴏʟᴀ 𝕤𝕠𝕞𝕖𝕥𝕙𝟚𝕤𝕒𝕪 (@jordisola_) October 2, 2021
I think he’s right. This setup is an implementation of the Command Query Responsibility Segregation (CQRS) pattern. Some non-database folks will argue that this is maybe the Wish variant, but I am actually a fan and I like it that way.
Takeaway
I needed that: A simple to deploy, non-over engineered project with actually some fun data.
There’s tons of things I want to explore in JDK 17 and now I have something to entertain me with in the coming winter evenings without much cycling.
As always, a sane mix is important. I wasn’t in the mood to build something for a while now but these days I am ok with that and I can totally accept it that my life consists of a broad things of topics and not only programming, IT and speaking about those topics. Doesn’t make anyone a bad developer if they don’t work day and night. With the nice nudge and JDK 17 just been released, it really kicked me.
If you’re interested in the actual application: I am running it here: charts.michael-simons.eu. Nope, it isn’t styled and yes, I am not gonna change it in the foreseeable future. That’s not part of my current focus.
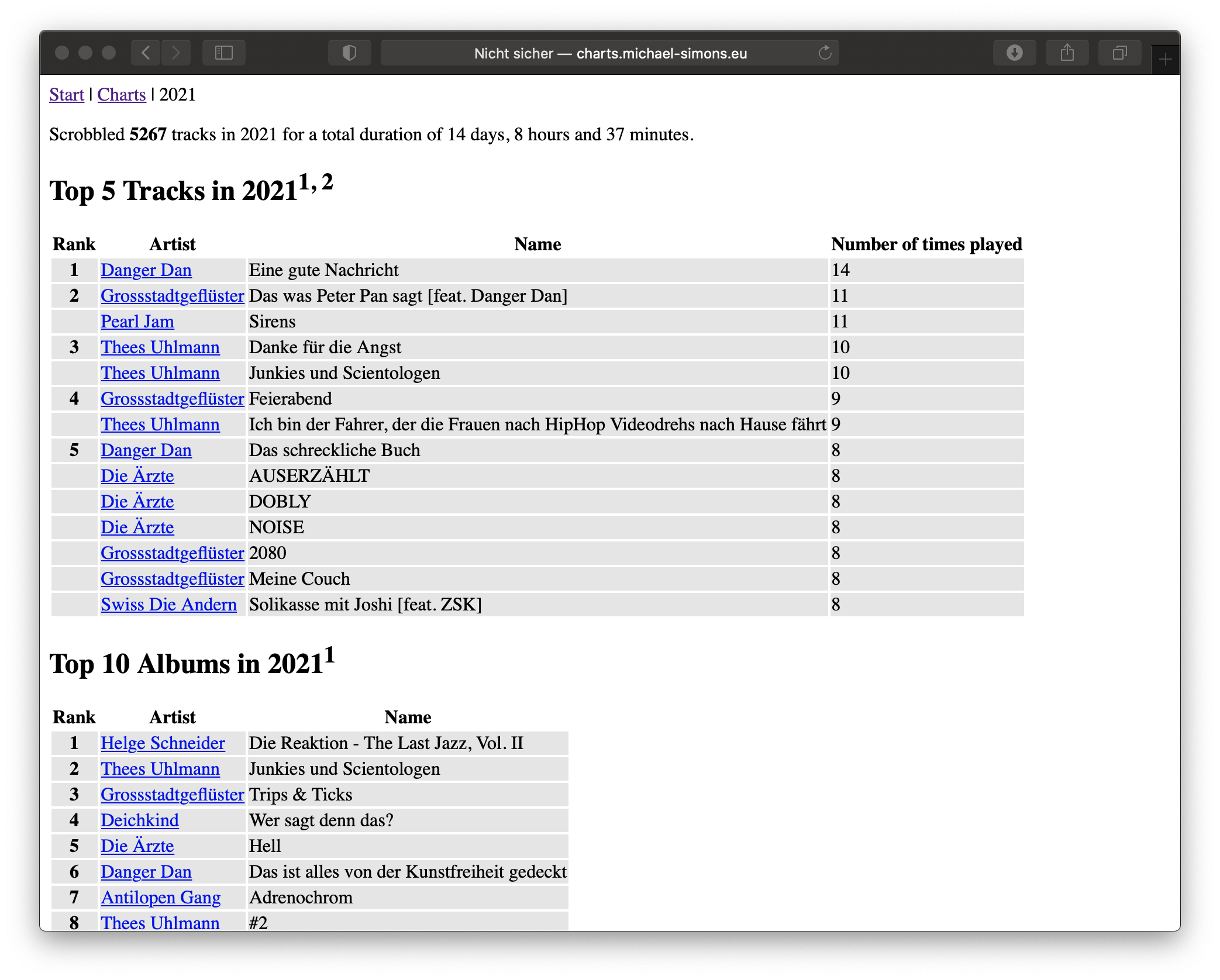
Next steps will be replacing my old AppleScript based scrobbler with a source/sink pair. And eventually, I will add a writing endpoint to the new application.




No comments yet
3 Trackbacks/Pingbacks
[…] >> Yet Another Incarnation of My Ongoing Scrobbles [info.michael-simons.eu] […]
[…] the beginning of this months, I wrote about a small tool I wrote for myself, scrobbles4j. I want the client to be able to run on the module path and the module path alone. Why am I doing […]
[…] talks about the domain model, turning it into a graph and I have a chart page up and running since 2021. Yes, this is of value to me. Not live altering, but a nice thing. I don’t need more AI and […]
Post a Comment