Modeling a domain with Spring Data Neo4j and OGM
This is the forth post in this series and I want to keep it short and simple.
A domain can be modeled in many ways and so can databases. As long as I deal with them, I always preferred the approach: Database (model) first. Usually, data is much longer around than applications and I don’t want my first application instance or version define the model for all eternity.
Using an Object-Graph-Mapper or Object-Relational-Mapper can be slightly danger. One tends to write down some class hierarchy and just let the tool do its magic. In the end, there are schemes that sometimes are very hard to read for humans. The danger might be a bit smaller with an OGM as hierarchies and connections map quite nicely onto a graph, but still, I don’t want that to be the default.
My domain can be summarized with a few sentences:
- There are Artists, that might be highlighted as Bands or Solo Artists
- Bands have Member
- Bands are founded in and solo artists are born in countries
- Sometimes Artists are associated with other Artists
- Albums are released by Artists in a year which is part of a decade
- Albums contain multiple tracks that have been played several times in a month of a given year
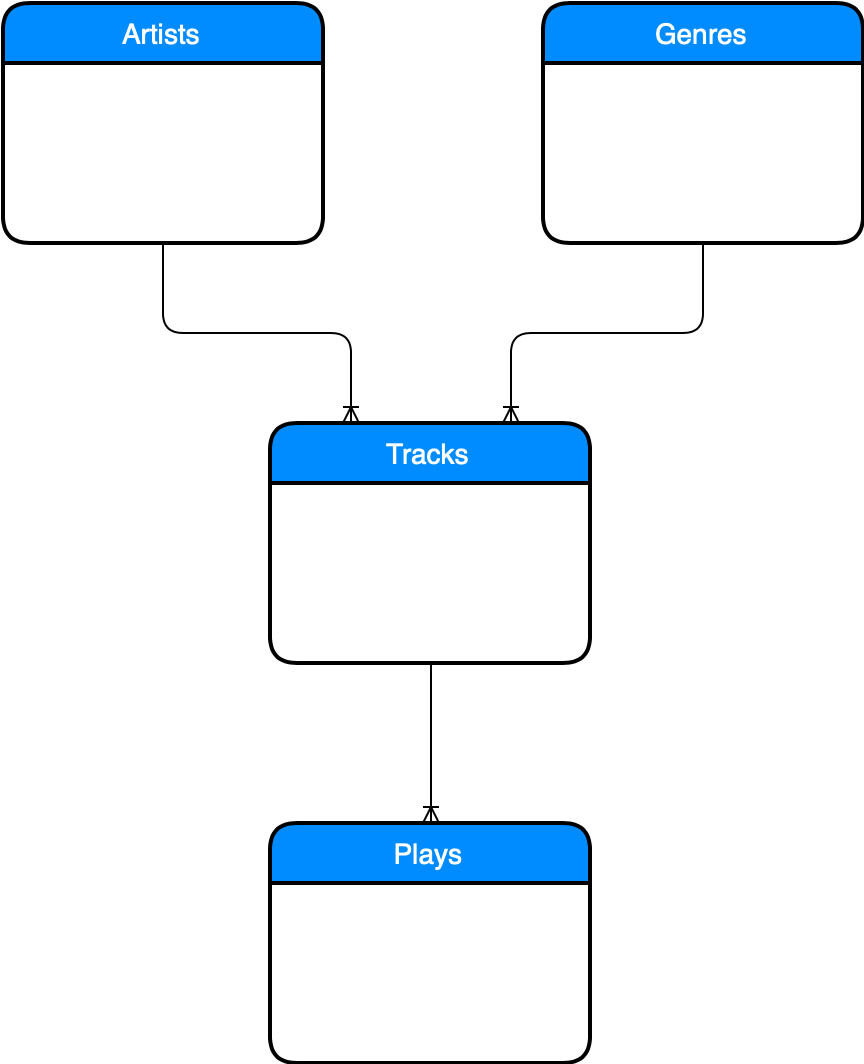
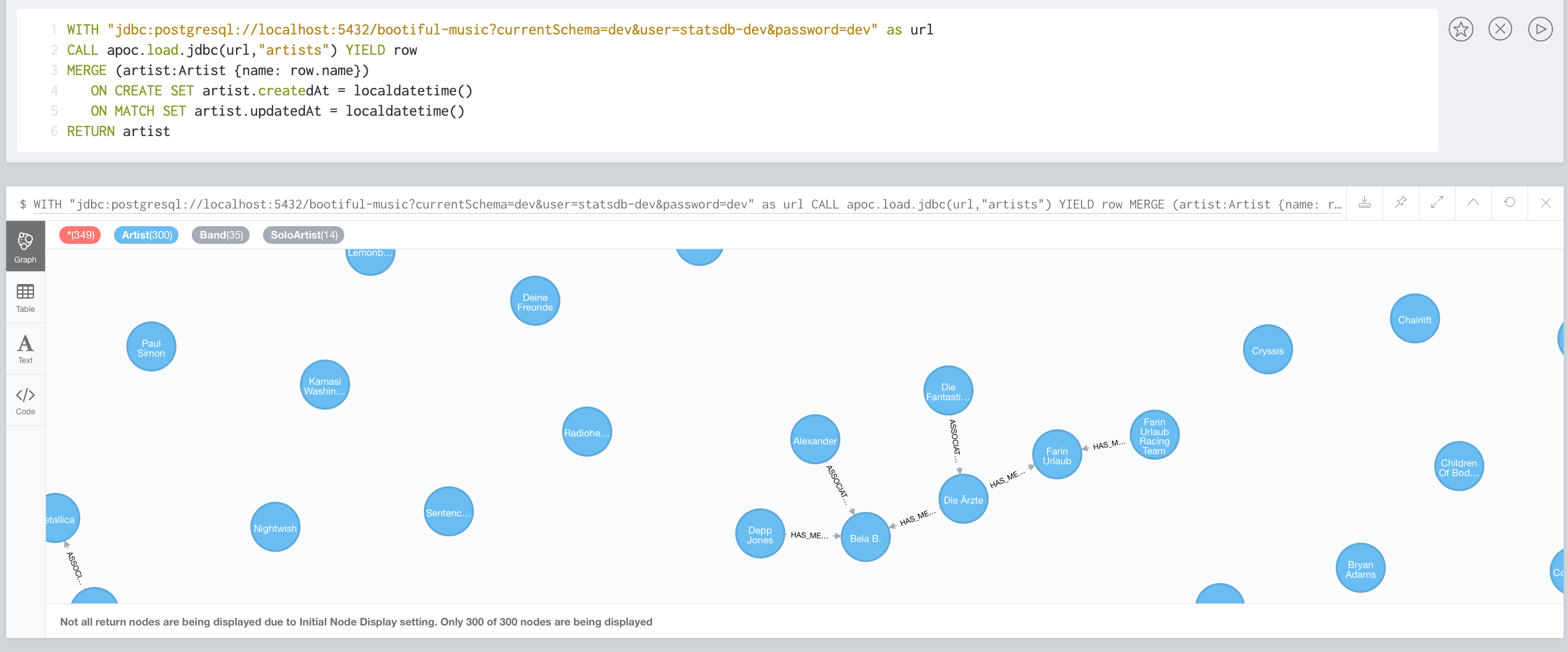
I spare you the logical ER-diagram for a relational database here and jump straight to the nodes. I highlighted all the important “classes” and their relations.
Modelling data with Neo4j feels a lot like modeling on a whiteboard. And actually, it really is: The whiteboard model ends up being the physical model in the end with Neo4j.
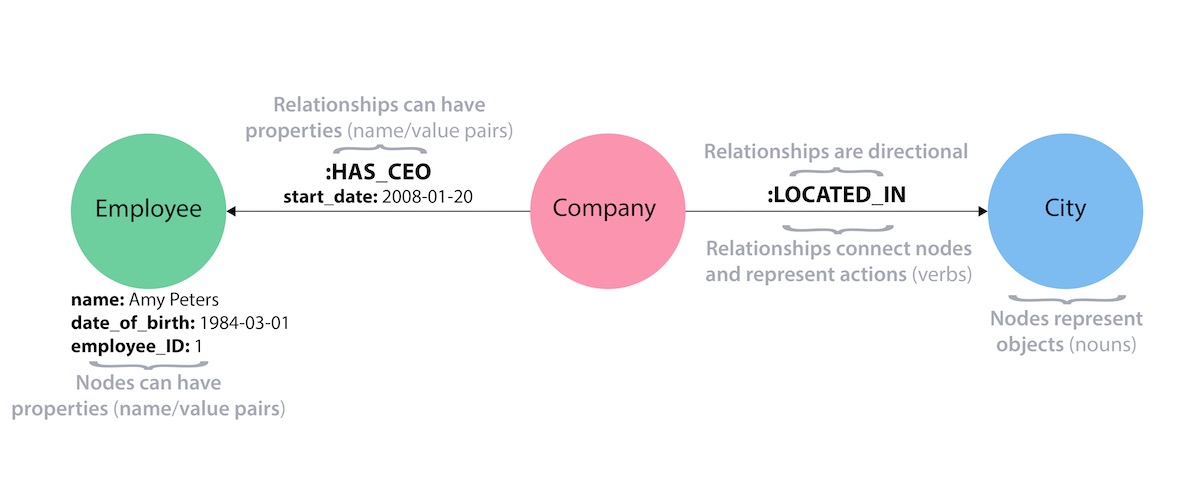
Neo4j is a property graph database. It stores Nodes with one or more Labels, their Relationships with a type among each other and properties for both nodes and relationships.
A label starts with a colon and is usually written with a initial upper case letter, i.e. :Artist and :Album, the type of a relationship is written with a colon and than all uppercase, :RELEASED_BY and properties in camel case, without a colon, i.e. name and firstName. The above list translates in my application to a model like this:
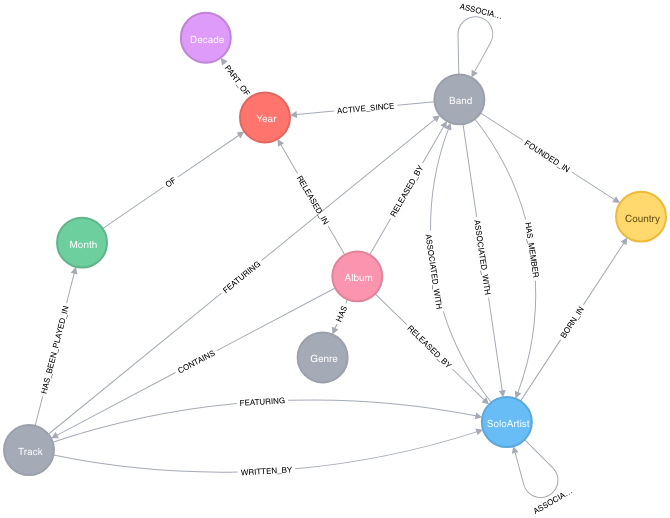
I really find it fascinating how that model reads: Pretty much the same as my verbal description.
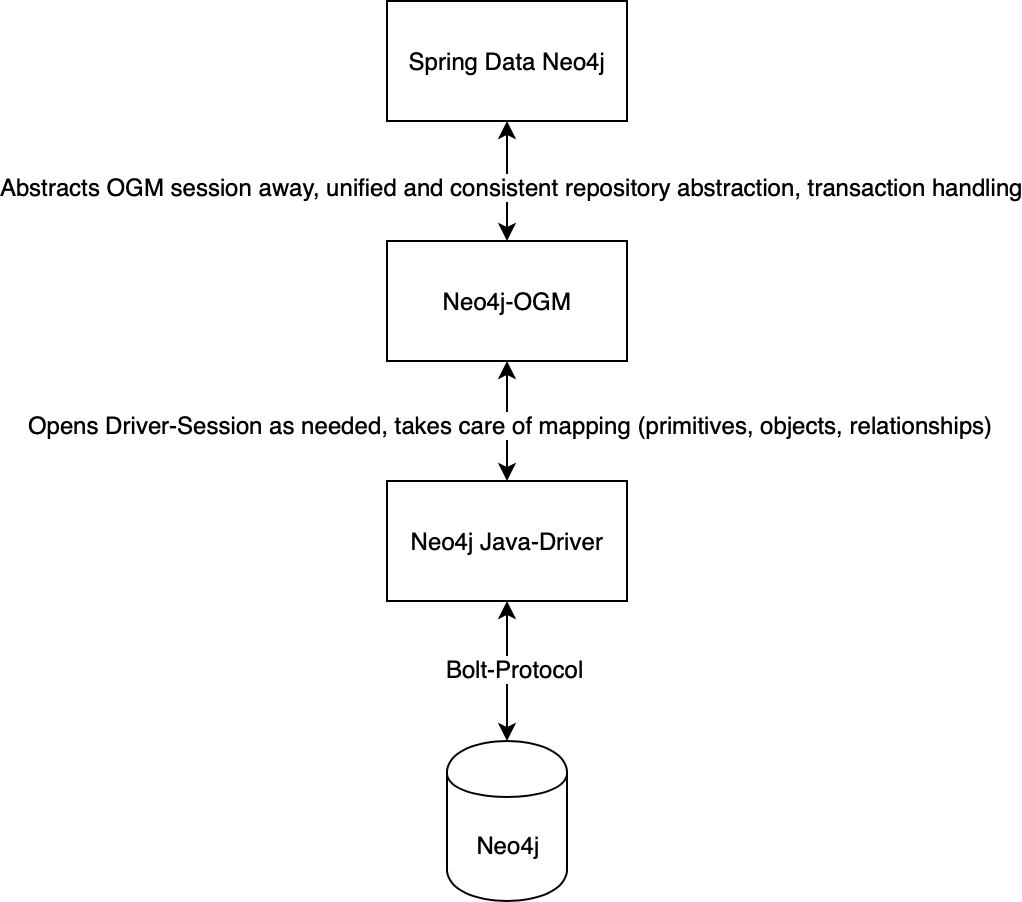
How to model this with Neo4-OGM and Spring Data Neo4j? You might want to recap the previous post to get an idea of the moving parts.
Value objects that happen to be persisted
In my domain the most simple objects are probably the year and the decade of the year. Those objects are value objects, they don’t have an identity. A year with a given value is as good as another instance with the same value.
@NodeEntity("Decade") public class DecadeEntity { @Id @GeneratedValue private Long id; @Index(unique = true) private long value; public DecadeEntity(long value) { this.value = value; } } @NodeEntity(label = "Year") public class YearEntity { @Id @GeneratedValue private Long id; @Index(unique = true) private long value; @Relationship("PART_OF") private DecadeEntity decade; YearEntity(final DecadeEntity decade, final long value) { this.decade = decade; this.value = value; } } |
I did model both of them to use them further on in aggregates, for example in the relationship RELEASED_IN, but I don’t see providing dedicated repositories for them. They only have a meaning in connection with other nodes. Things to notice here are: I followed a naming convention: All classes that are mapped to something inside the graph ends in “Entity”. Thus I have to use label attribute of @NodeEntity (or the default attribute) to specify a “nice” label, i.e. @NodeEntity(label = "Year"). I use @Index for completeness. One can configure Neo4j-OGM to automatically create indexes, but TBH, I prefer to create them by hand. There’s also one outgoing relationship from year to decade. A year is part of a decade: @Relationship("PART_OF").
You also notice that I didn’t model any of the other outgoing relationships from the year: Like all the albums released in this year, all the months with play counts in that year or the foundation years of band.
While all of Neo4j, Neo4j-OGM and Spring Data Neo4j could map relationships many levels deep, I don’t think it’s wise from an application performance point of view. I’d rather explicitly select the stuff I need.
A common base class for aggregates
I’m known for my dislike of having common base entities:
I like it a lot. Still having a hard time to understand why introducing "Base entities". I often see this, mainly for an ID column and some auditing. Heck, I even added one to a Spring Data Neo4j example myself to see if our code works as advertised.
— Michael Simons (@rotnroll666) October 11, 2018
For this project however, I included one for several reasons: To not pester every other entity with the technical id, to audit interesting entities and plain simple, to have an example that actually uses our (Spring Data Neo4j) support of Spring Data’s auditing in inheritance scenarios. This is what the class looks like:
public abstract class AbstractAuditableBaseEntity { @Id @GeneratedValue // 1 private Long id; @CreatedDate // 2 @Convert(NoOpLocalDateTimeConversion.class) // 3 private LocalDateTime createdAt; @LastModifiedDate // 2 @Convert(NoOpLocalDateTimeConversion.class) private LocalDateTime updatedAt; } |
- Maps Neo4j’s technical (internal) id to an attribute
- Audits the creation respectively modification date of an entity
- Due to some issues with the transport, we have to force Neo4j-OGM here to not convert anything. Neo4j 3.4 supports Java 8 time types natively
Simple aggregates or entities
I see something like the Genre as a simple entity:
@NodeEntity("Genre") public class GenreEntity extends AbstractAuditableBaseEntity { @Index(unique = true) private String name; public GenreEntity(String name) { this.name = name; } } |
It is useful to maintain on its own, has an identity but no mapped relationships. I usually declare a repository for such an entity:
import org.springframework.data.neo4j.repository.Neo4jRepository; public interface GenreRepository extends Neo4jRepository<GenreEntity, Long> { } |
While it’s often preferable to extend such a repository interface not from the concrete store, I do think it’s better having the concrete store at hand in the case of Neo4j. While the concrete implementation brings a lot of CRUD method one doesn’t need all the time, it also brings in overloaded versions of them that take the depth into account as well.
To mitigate the large surface of repository methods, it’s often a good idea to reduce the repositories visibility to a minimum.
I don’t see a problem using such an entity and repository directly from a controller, for example like this:
@Controller @RequestMapping("/genres") public class GenreController { private final GenreRepository genreRepository; public GenreController(GenreRepository genreRepository) { this.genreRepository = genreRepository; } @GetMapping(value = { "", "/" }, produces = MediaType.TEXT_HTML_VALUE) public ModelAndView genres() { var genres = this.genreRepository.findAll(Sort.by("name").ascending()); return new ModelAndView("genres", Map.of("genres", genres)); } @GetMapping(value = "/{genreId}", produces = MediaType.TEXT_HTML_VALUE) public ModelAndView genre(@PathVariable final Long genreId) { var genre = this.genreRepository.findById(genreId) .orElseThrow(() -> new NodeNotFoundException(GenreEntity.class, genreId)); var model = Map.of( "genreCmd", new GenreCmd(genre), "genre", genre ); return new ModelAndView("genre", model); } @PostMapping(value = { "", "/" }, produces = MediaType.TEXT_HTML_VALUE) public String genre(@Valid final GenreCmd genreForm, final BindingResult genreBindingResult) { if (genreBindingResult.hasErrors()) { return "genre"; } var genre = Optional.ofNullable(genreForm.getId()) .flatMap(genreRepository::findById) .map(existingGenre -> { existingGenre.setName(genreForm.getName()); return existingGenre; }).orElseGet(() -> new GenreEntity(genreForm.getName())); genre = this.genreRepository.save(genre); return String.format("redirect:/genres/%d", genre.getId()); } static class GenreCmd { private Long id; @NotBlank private String name; GenreCmd(GenreEntity genreEntity) { this.id = genreEntity.getId(); this.name = genreEntity.getName(); } public GenreCmd() { } public Long getId() { return this.id; } public String getName() { return this.name; } public void setId(Long id) { this.id = id; } public void setName(String name) { this.name = name; } } } |
Find the sources here: GenreEntity, GenreRepository and the GenreController.
One use case is definitely “give me all the albums having a specific main genre.” To implement such a case, I rather access that sub collection from the owning site of the relationship. Here, the albums:
@NodeEntity("Album") public class AlbumEntity extends AbstractAuditableBaseEntity { @Relationship("RELEASED_BY") private ArtistEntity artist; private String name; @Relationship("RELEASED_IN") private YearEntity releasedIn; @Relationship("HAS") private GenreEntity genre; private boolean live = false; public AlbumEntity(ArtistEntity artist, String name, YearEntity releasedIn) { this.artist = artist; this.name = name; this.releasedIn = releasedIn; } } |
The repository for that entity declares a method like this:
interface AlbumRepository extends Neo4jRepository<AlbumEntity, Long> { List<AlbumEntity> findAllByGenreNameOrderByName(String name, @Depth int depth); } |
It makes use of Spring Data Neo4j’s traversal feature: It traverses the relationship from album to genre and asks for all albums having a relationship of type “HAS” to a genre with the given name.
That’s also a method that I’d wrap in a service, as the method name is super technical and I don’t want that:
@Service public class AlbumService { private final AlbumRepository albumRepository; public List<AlbumEntity> findAllAlbumsWithGenre(GenreEntity genre) { return albumRepository.findAllByGenreNameOrderByName(genre.getName(), 1); } } |
Complex aggregates
The Artist is a complex thing. It exists in three different forms: An unspecified artist, solo artist and as bands.
While Neo4j-OGM allows you to add a list of labels to your domain and thus allowing one entity to be mapped to several labels, I don’t like that approach.
Bands and solo artists have quite different attributes, as you can see in the sources linked above and I don’t want them to mix up.
By declaring the Artist class with @NodeEntity("Artist") and the band, which extends from it, with @NodeEntity("Band") and solo artist accordingly, bands and solo artists are stored with this two labels. Polymorphic queries works to some extend with a repository for the base entity, but as Neo4j-OGM applies schema based loading, stuff can be missing from the result.
While polymorphic queries are not a daily use case, this one is:
A band has one or more members:
@RelationshipEntity("HAS_MEMBER") public static class Member { @Id @GeneratedValue private Long memberId; @StartNode private BandEntity band; @EndNode private SoloArtistEntity artist; @Convert(YearConverter.class) private Year joinedIn; @Convert(YearConverter.class) private Year leftIn; Member(final BandEntity band, final SoloArtistEntity artist, final Year joinedIn, final Year leftIn) { this.band = band; this.artist = artist; this.joinedIn = joinedIn; this.leftIn = leftIn; } } |
And in BandEntity:
@NodeEntity("Band") public class BandEntity extends ArtistEntity { @Relationship("FOUNDED_IN") private CountryEntity foundedIn; @Relationship("ACTIVE_SINCE") private YearEntity activeSince; @Relationship("HAS_MEMBER") private List<Member> member = new ArrayList<>(); public BandEntity(String name, @Nullable String wikidataEntityId, @Nullable CountryEntity foundedIn) { super(name, wikidataEntityId); this.foundedIn = foundedIn; } BandEntity addMember(final SoloArtistEntity soloArtist, final Year joinedIn, final Year leftIn) { Optional<Member> existingMember = this.member.stream() .filter(m -> m.getArtist().equals(soloArtist) && m.getJoinedIn().equals(joinedIn)).findFirst(); existingMember.ifPresentOrElse(m -> m.setLeftIn(leftIn), () -> { this.member.add(new Member(this, soloArtist, joinedIn, leftIn)); }); return this; } public List<Member> getMember() { return Collections.unmodifiableList(this.member); } } |
As you see: No setters for the member and a getter that returns an unmodifiable list. Thus adding (and removing) members goes only through the band. The modified band is then returned. As Neo4j-OGM and Spring Data Neo4j don’t do dirty tracking and don’t save things automatically at the end of a transaction, we have to take care here. Again, I recommend a service layer:
@Service public class ArtistService { @Transactional public BandEntity addMember(final BandEntity band, final SoloArtistEntity newMember, final Year joinedIn, @Nullable final Year leftIn) { return this.bandRepository.save(band.addMember(newMember, joinedIn, leftIn)); } } |
This is again from ArtistService.
To close this up, one final example: When entities are being deleted through Neo4j-OGM, it deletes only relationships, not the target nodes of the relationships. You have to decide wether you want “dangling” nodes in your database or not. Sometimes this is ok, sometimes not. As of today, Neo4j itself has no foreign key constraint on the relationship. And how so? It’s complete ok that a node exists for its own.
In my domain here however, albums without an artist and tracks without albums serve no purpose. To delete them when I delete an artist, I do this again through a service. The session in the following snippet is the autowired OGM session. It’s completely ok to access it. Spring Data Neo4j takes care that it participates in ongoing transactions:
@Service public class ArtistService { private final Session session; @Transactional public void deleteArtist(Long id) { this.findArtistById(id).ifPresent(a -> { session.delete(a); session.query("MATCH (a:Album) WHERE size((a)-[:RELEASED_BY]->(:Artist))=0 DETACH DELETE a", Map.of()); session.query("MATCH (t:Track) WHERE size((:Album)-[:CONTAINS]->(t))=0 DETACH DELETE t", Map.of()); session.query("MATCH (w:WikipediaArticle) WHERE size((:Artist)-[:HAS_LINK_TO]->(w))=0 DETACH DELETE w", Map.of()); }); } } |
Yes, there is Cypher hidden away in a class. Sometimes there are compromises to be taken, and this one is a comprise that’s ok for me. There’s also JCypher, maybe that would be something to try out in the future.
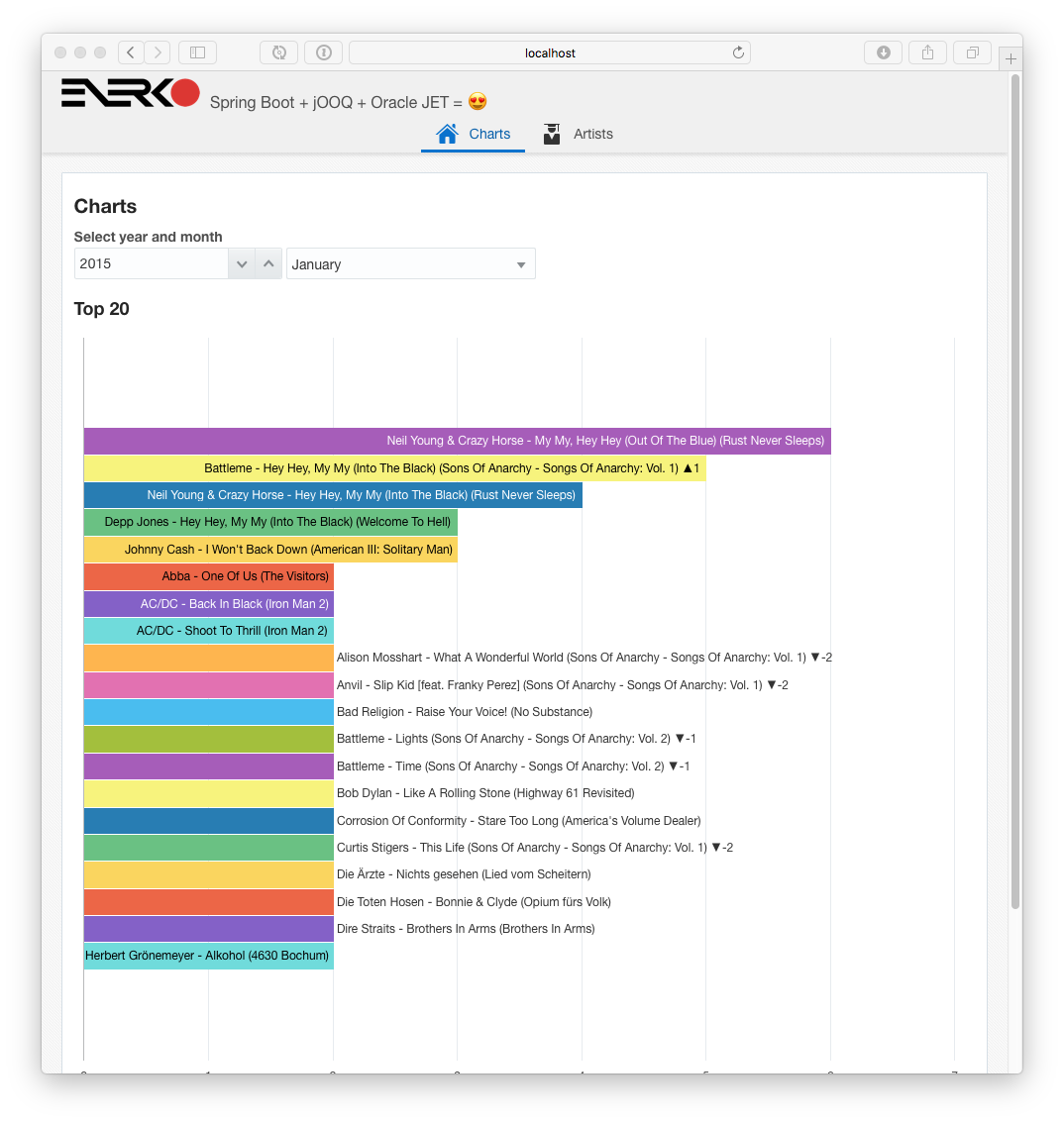
With all the things here in this post, it’s easy to write a nice application, that deals not only with CRUD, but already presents all the interesting associations:
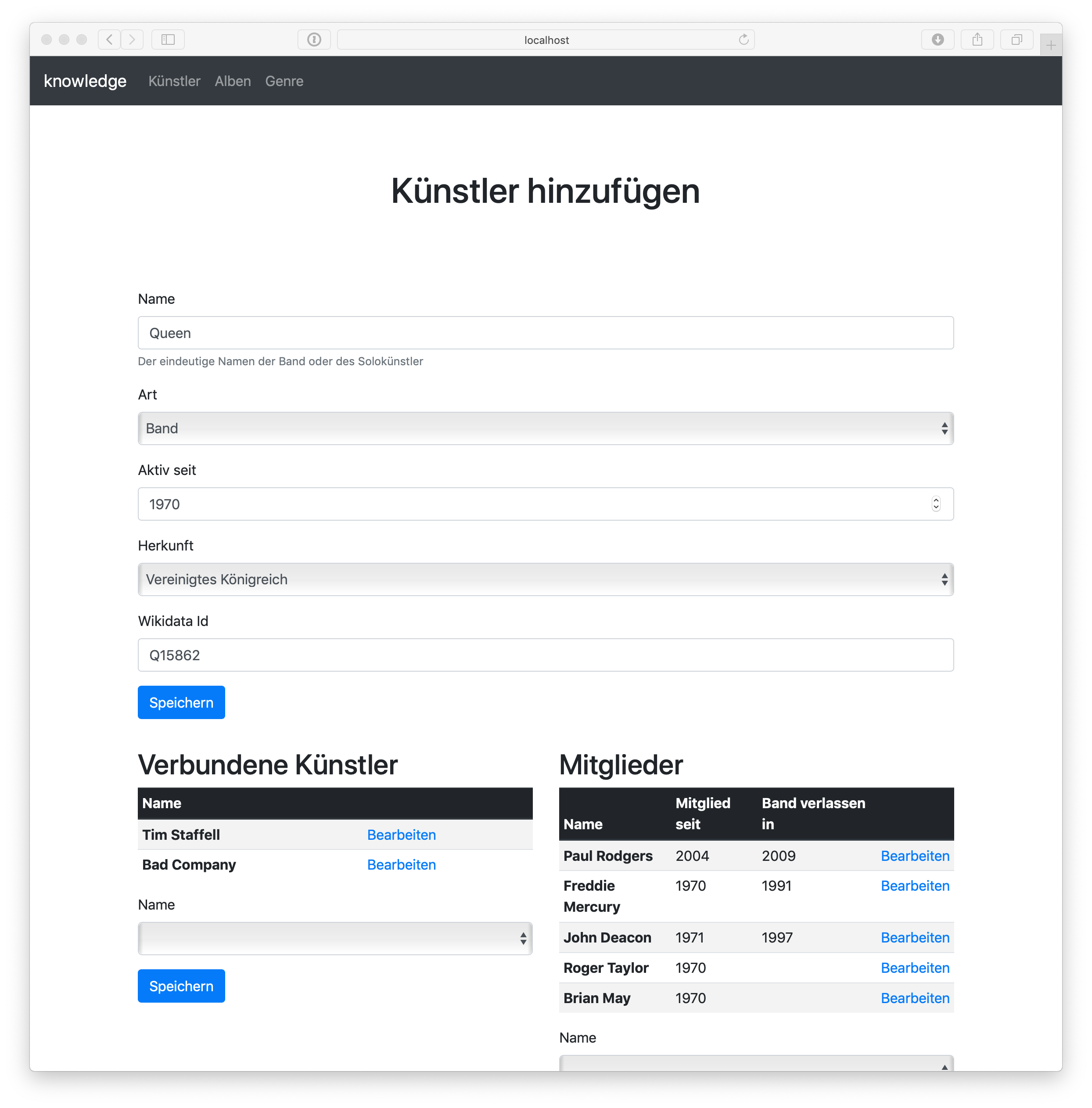
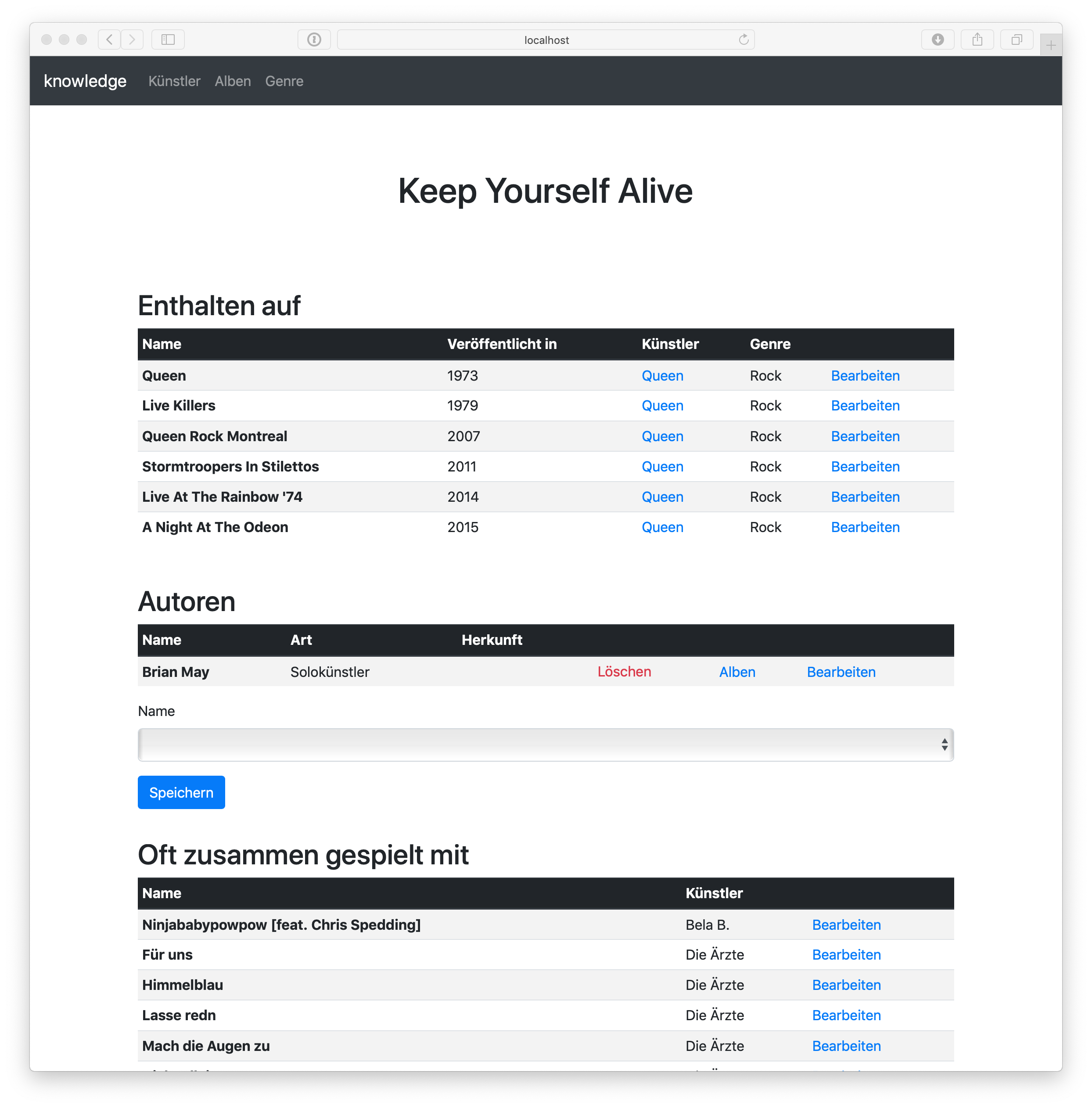
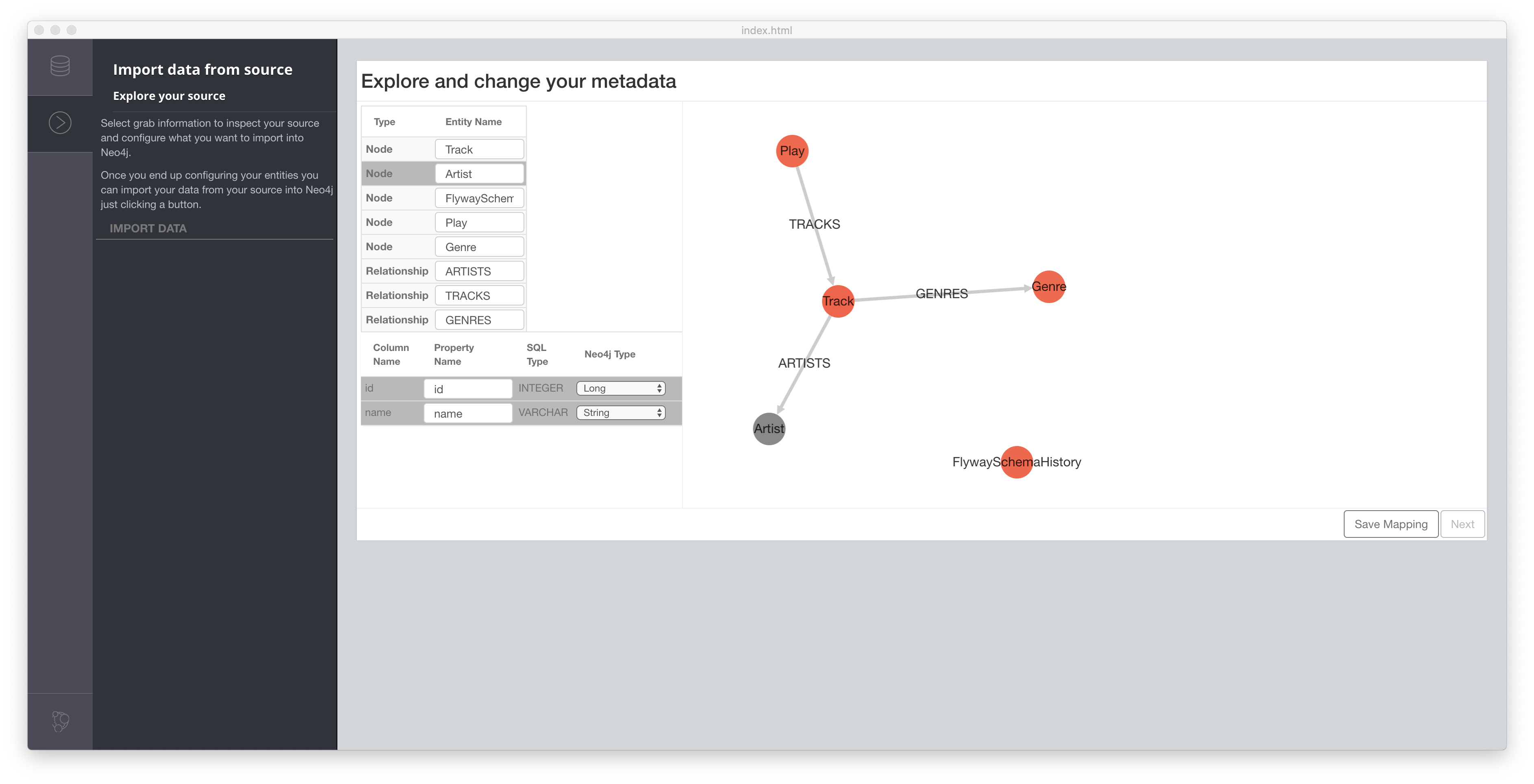
The complete application is available on GitHub as “bootiful music”. It has some rough edges, also ops wise, but the repository along with the posts of this series should help to get you started.
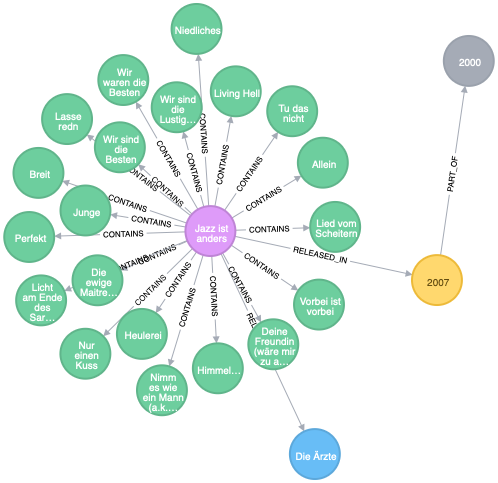
I’d like to thank Michael a lot for the idea of this query, which results in nice micro genres or categories:
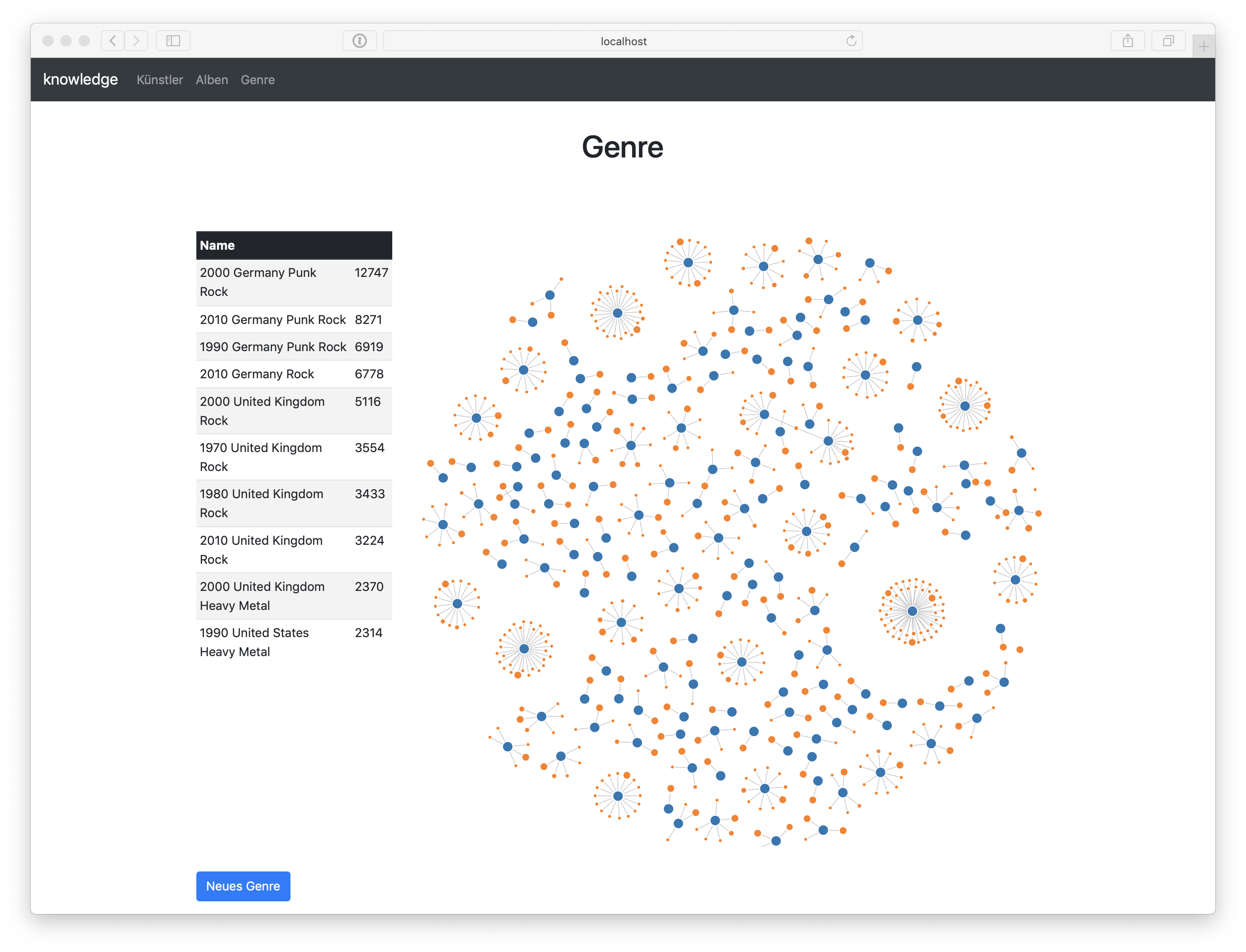


{kind=link}
{kind=link}