This is the second post in the series of From relational databases to databases with relations. Check the link to find all the other entries, too. The source code for everything, including the relational dataset is on GitHub: https://github.com/michael-simons/bootiful-music.
The post has also been featured in This Week in Neo4j.
To feel comfortable in a talk, I need to have a domain in front of me I’m familiar with. Neo4j just announced the Graph Gallery which is super nice to explore Graphs, but I wanted to have something of my own and I keep continue using the idea of tracking my musical habits. In the end I want to have knowledge base in addition to my chart applications (both linked above).
There are several ways to get data into your Neo4j database. One is a simple Cypher statement like this
CREATE (artist:Artist {name: 'Queen'}) RETURN artist |
which creates a node with the label Artist and a property name for one of my favorite bands of all time. I can use the MERGE statement, which ensures the existence of a whole pattern (note only a node), too. More on that later, though. In any case, that would be a real effort todo manually. Therefor, let’s have a look how to import data. I found several options:
- Importing CSV Data into Neo4j
- Importing JSON into Neo4j
- Importing data with JDBC into Neo4j
- Using the Neo4j ETL Tool
- Writing your own tool
I find it quite fascinating in how many ways CSV data can be processed from within Neo4j itself. It reads through CSV and provides each row in a way that you can interact with from a Cypher statement like it comes from the graph itself. Those CSV files can be put into a dedicated import folder in the database instance but can also be retrieved from a URL. You can come a long way with that import if you already have CSV or a willing to massage your data a bit so that it fits a plain structure. Rik did this with a beer related data, check it out here: Fun with Beer – and Graphs in Part 1: Getting Beer into Neo4j.
JSON is an option if you want to work agains the many nice APIs out there, but my data sits in a relational database. It looks like this:
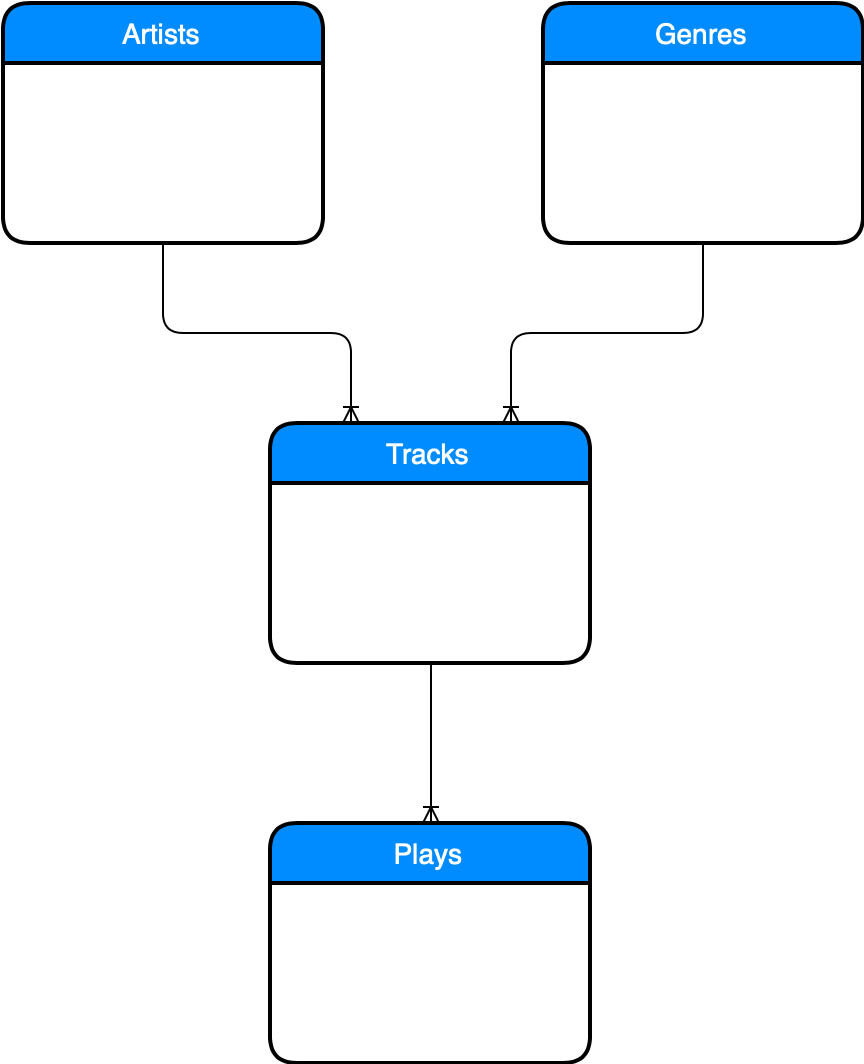
This tables store all tracks I have listened to, their artists and genres and in a time series table all plays. If you read the previous post closely, you’ll notice that this database, dubbed statsdb is only in NF2. There is no separate relation for the albums of an artist. They are stored with the tracks. I actually forgot why I modeled it that way. I vaguely remember that I was enjoyed that album names are not necessarily unique and I could find a good business primary key. Anyway, the schema is still running and gives me each month something like that which btw takes only three SQL queries:

In my property graph model I wanted to have separate albums nodes, though, so I had to massage and aggregate my data a bit before creating nodes. As I didn’t want to do this based on CSV, I looked at all the options JDBC. First, Neo4j ETL Tool:
Neo4j ETL Tool
The Neo4j ETL Tool can be downloaded through Neo4j Desktop and needs a free activation key. The link guides you through all the steps necessary to connect the tool to both the Graph database as well as the relational database. The nice thing here: You don’t have to install a driver for popular databases like MySQL or PostgreSQL as it comes with our tool.
I ran the tool agains my database and stopped here:
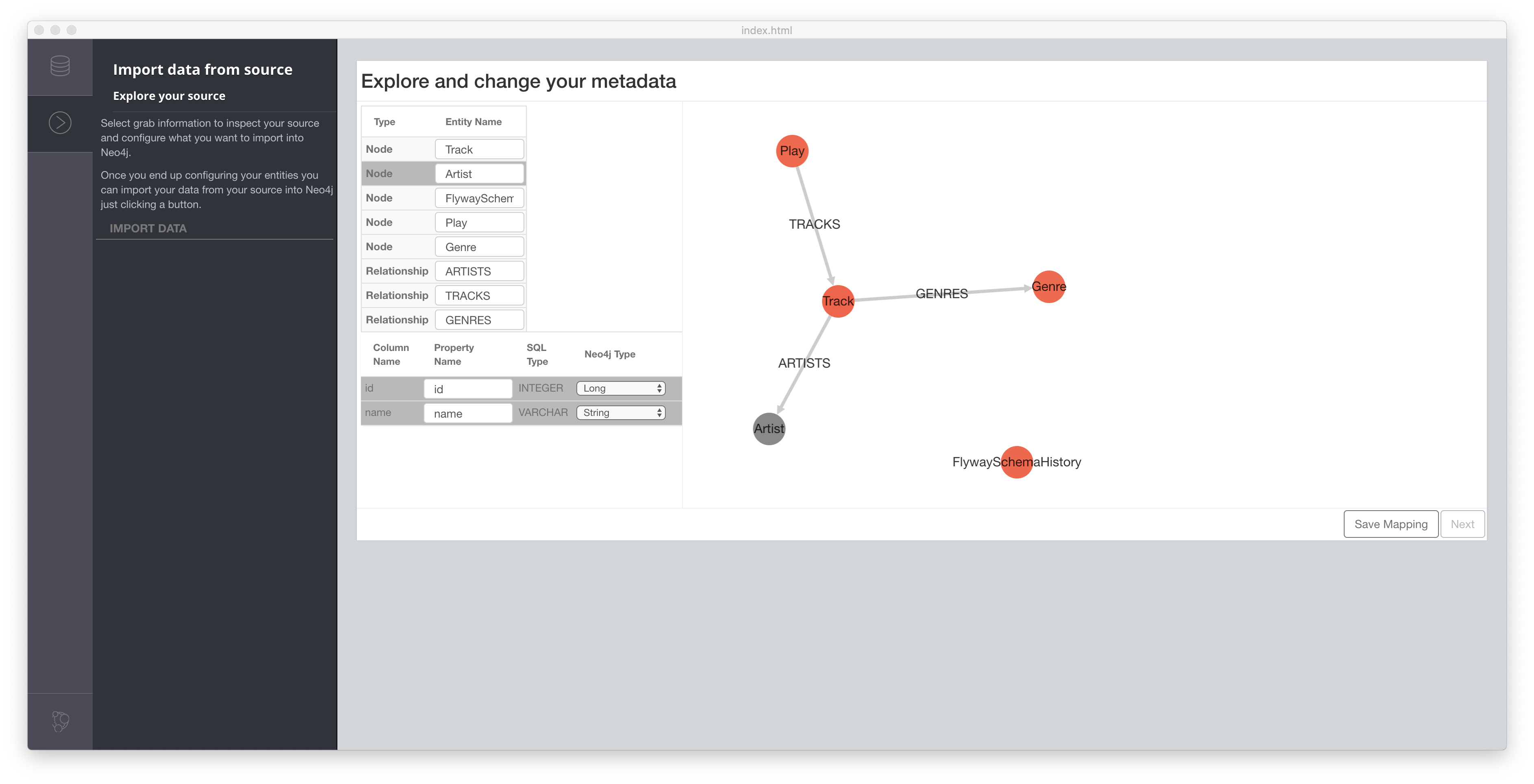
The ETL Tool recognized my tables and also the foreign keys and proposed a node and relationship structure. This is nice, but doesn’t fit exactly what I want. The relationships can easily be renamed and so can the node labels, but I don’t want the structure. I could just ran this and than transform everything via Cypher again, but that feels weird.
What I want is something like this (plus the play counts, for sure):
MATCH path1=(album:Album {name: 'Jazz ist anders'}) - [:RELEASED_BY] -> (:Artist)
MATCH path2=(album) - [:RELEASED_IN] -> (:Year) - [:PART_OF] -> (:Decade)
MATCH (album) - [:CONTAINS] -> (tracks:Track)
RETURN path1, path2, tracks |
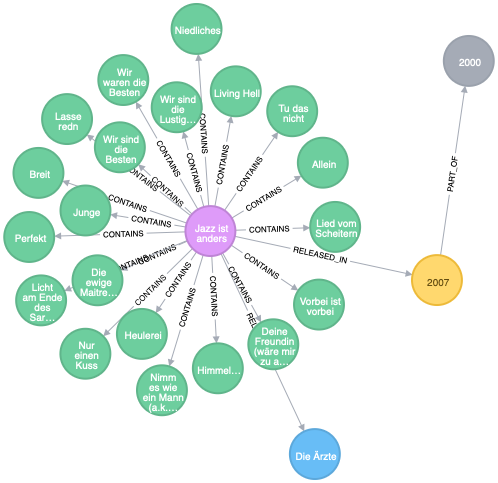
Getting all the artists is simple. It’s basically a “select * from artists” and the corresponding Cypher. This is what Apoc does:
Importing data with JDBC into Neo4j
APOC is not only the name of a technician in the famous Movie “The Matrix”, but also an acronym for “Awesome Procedures on Cypher”. Neo4j is extensible via custom, stored procedures and functions much like PostgreSQL and Oracle. I have been a friend of those for years, I even read and generated Microsoft Excel files from within an Oracle Database. Now I realize, that Michael Hunger does the same for Neo4j 🙂
Anyway. APOC offers “Load JDBC” and Michael has a nice introduction at hand.
To use APOC you have to find the plugin folder of your Neo4j installation. Download the APOC release matching your database version from the above GitHub link and add it to the plugin folder. APOC doesn’t distribute the JDBC drivers itself, those have to be installed as well. As my stats db is PostgreSQL, I grabbed the PostgreSQL JDBC Driver and put it into the plugin folder as well.
Things are super easy from there on. With the following Cypher statement, the Neo4j instances connects agains the PostgreSQL instance, executes a select * from artists and returns each row. YIELD is a subclause to CALL and selects all nodes, relationships or properties returned from the procedure for further processing as bound variables in a Cypher query. I then used them to merge all artists. In case they already existed, I updated some auditing attributes. The associations between some artists have already been there, so merge didn’t remove that:
WITH "jdbc:postgresql://localhost:5432/bootiful-music?currentSchema=dev&user=statsdb-dev&password=dev" as url
CALL apoc.load.jdbc(url,"artists") YIELD row
MERGE (artist:Artist {name: row.name})
ON CREATE SET artist.createdAt = localdatetime()
ON MATCH SET artist.updatedAt = localdatetime()
RETURN artist |
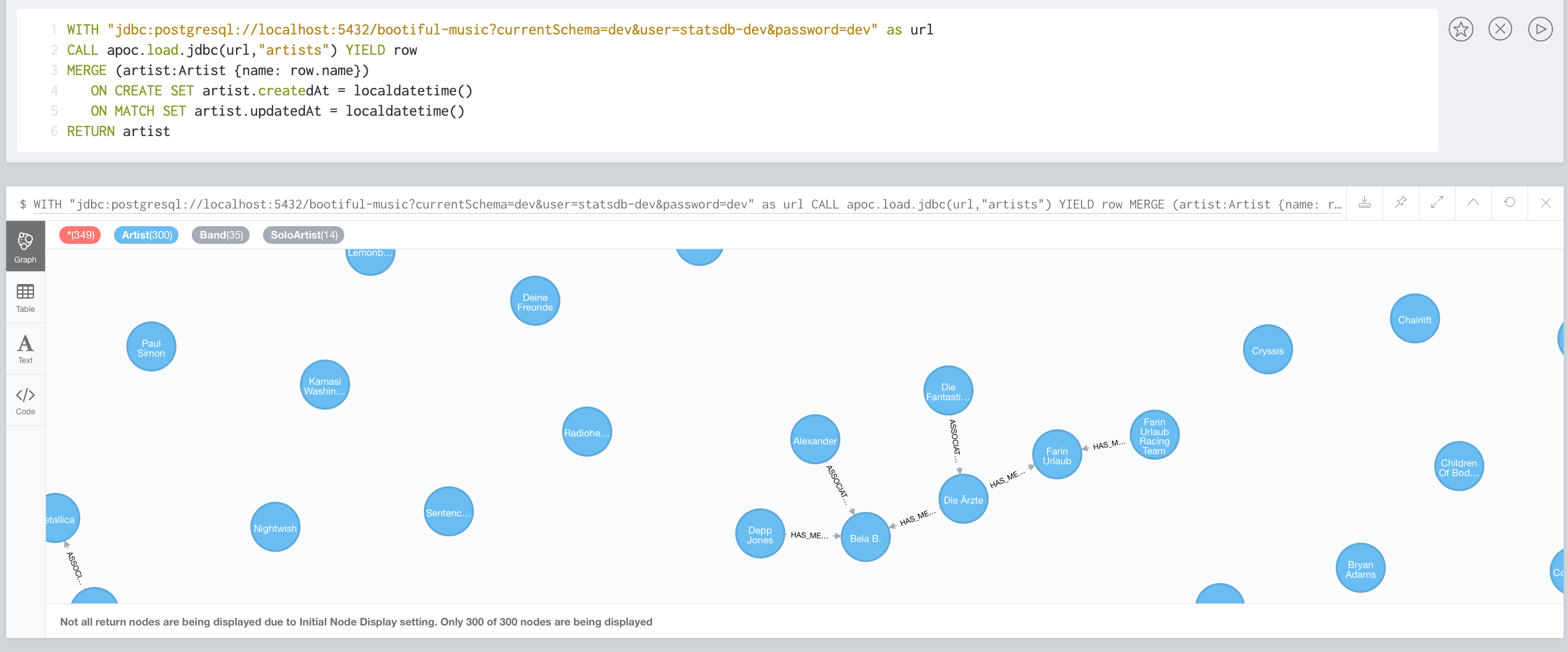
The merge-clause is really fascinating. It matches a pattern and the merge is applied to the full pattern, meaning it must exist as a whole. In the case above, the pattern is simple, it’s just a single node. If you want to create or update an album released by an artist and use something like this MERGE (album:Album {name: $someAlbumName}) - [:RELEASED_BY] -> (artist:Artist {name: $someNewArtistName}), the statement will always create a new artist node, regardless wether the artist already exists or not as the whole pattern is checked. You have to do those things in separate steps like this:
MERGE (artist:Artist {name: $someNewArtistName})
MERGE (album:Album {name: $someAlbumName}) - [:RELEASED_BY] -> (artist) |
First, merge the artist. Then, merge the album and the relationship to the existing artist node. For me, coming from with SQL background, this feels unusual at first, much like I can use something in an imperative AND declarative way.
Now, the above example is still not what I want. apoc.load.jdbc basically gives me the whole table and I have to do every post-processing in afterwards. Luckily, that second parameter can also be a full SQL statement. Now, to create a graph structure like above (minus the tracks though), I did something like this. Behold, all the SQL and Cypher in one statement:
WITH "jdbc:postgresql://localhost:5432/bootiful-music?currentSchema=dev&user=statsdb-dev&password=dev" as url,
"SELECT DISTINCT a.name as artist_name, t.album, g.name as genre_name, t.year
FROM tracks t JOIN artists a ON a.id = t.artist_id JOIN genres g ON g.id = t.genre_id
WHERE t.compilation = 'f'" as sql
CALL apoc.load.jdbc(url,sql) YIELD row
MERGE (decade:Decade {value: row.year-row.year%10})
MERGE (year:Year {value: row.year})
MERGE (year) - [:PART_OF] -> (decade)
MERGE (artist:Artist {name: row.artist_name})
ON CREATE SET artist.createdAt = localdatetime()
ON MATCH SET artist.updatedAt = localdatetime()
MERGE (album:Album {name: row.album}) - [:RELEASED_BY] -> (artist)
ON CREATE SET album.createdAt = localdatetime()
ON MATCH SET album.updatedAt = localdatetime()
MERGE (genre:Genre {name: row.genre_name})
ON CREATE SET genre.createdAt = localdatetime()
ON MATCH SET genre.updatedAt = localdatetime()
MERGE (album) - [:HAS] -> (genre)
MERGE (album) - [:RELEASED_IN] -> (year) |
Read: Bind the JDBC url and a SQL statement to variables. The sql selects a distinct set of all artists and album, including genre and year, thus denormalizing my relational schema by joining the artists and genres. The resulting tuples are then used to create decades and years, merge artists, genres and albums and finally relating them to each other. I was deeply impressed after I ran that.
First: It’s amazing how well Neo4j integrates with other stuff and secondly, it’s actually pretty readable I think.
In my talk, I will dig deeper in the Cypher used. Also, the statements for generating the track data in the above Graph are bit more complex (you find them here). But in the end, I could have stopped here. And probably, I would have done so, if I had started with APOC in the beginning.
But me being the mad scientist I am, started somewhere else:
Writing your own tool
I did this right after my first look at the ETL tool. Neo4j can be extended with procedures and functions. Procedures stream a result with several attributes, functions return single values. When I joined Neo4j, my dear colleague Gerrit impressed me with knowledge about that stuff and I wanted to keep up with his pace, so I saw a good learning opportunity here.
One does not have to extend from a dedicated class or have to implement an interface for writing a Neo4j stored procedure. It’s enough to annotate the methods that should be exposed with either @Procedure or @UserFunction. It’s necessary that org.neo4j:neo4j is a provided dependency on the class path.
Neo4j provides detailed information how to create a package that just can be dropped into Neo4js plugin folder, find the instructions here. They worked as promised.
What I did was to apply one of my favorite libraries again, run jOOQ against my stats database, generating a type safe DSL dedicated to my domain, packaged it up and than used it in a Neo4j stored procedure. In the following listing you’ll find that I use Neo4js @Context to get hold of the graph database service in which the procedure is running, pass in user name, password and JDBC url to my procedure. Those are used to connect against PostgresSQL (try (var connection = DriverManager.getConnection(url, userName, password);) {} (yeah, that’s Java 11 code), open a Neo4j transaction and than just executing my SQL and manually creating nodes.
public class StatsIntegration { @Context public GraphDatabaseService db; @Context public Log log; @Procedure(name = "stats.loadPlayCounts", mode = Mode.WRITE) @Description("Loads the play counts for tracks. Note: All the tracks and albums need to be there, use loadAlbumData before.") public void loadPlayCounts( @Name("userName") final String userName, @Name("password") final String password, @Name("url") final String url) { try (var connection = DriverManager.getConnection(url, userName, password); var neoTransaction = db.beginTx()) { var statsDb = DSL.using(connection); var isNoCompilation = TRACKS.COMPILATION.eq("f"); final String columnNameYear = "yearValue"; final String columnNameMonth = "monthValue"; final String columnNameNewPlayCount = "newPlayCount"; var year = extract(PLAYS.PLAYED_ON, DatePart.YEAR).as(columnNameYear); var month = extract(PLAYS.PLAYED_ON, DatePart.MONTH).as(columnNameMonth); log.info("Deleting existing playcounts"); executeQueryAndLogResults("MATCH (:Track) - [playCount:HAS_BEEN_PLAYED_IN] -> () DETACH DELETE playCount", Map.of()); log.info("Loading playcounts from statsdb"); statsDb .select( ARTISTS.NAME, TRACKS.NAME, year, month, count().as("newPlayCount") ) .from(PLAYS) .join(TRACKS).onKey() .join(ARTISTS).onKey() .where(isNoCompilation) .groupBy(ARTISTS.NAME, TRACKS.NAME, year, month) .forEach(r -> { var parameters = Map.of( "artistName", r.get(ARTISTS.NAME), "trackName", r.get(TRACKS.NAME), columnNameYear, r.get(columnNameYear), columnNameMonth, r.get(columnNameMonth), columnNameNewPlayCount, r.get(columnNameNewPlayCount) ); executeQueryAndLogResults(CREATE_PLAY_COUNTS, parameters); }); log.info("Adding weight to artists"); executeQueryAndLogResults(WEIGHT_ARTISTS_BY_PLAYCOUNT, Map.of()); neoTransaction.success(); } catch (Exception e) { e.printStackTrace(); } } } |
The complete sources for that exercise are in the etl module of my project. As interesting as the stored procedure itself is the integration test, that needs both a Neo4j instance and PostgreSQL. For the first I use our own test harness for the later one, Testcontainers.
Conclusion
As much as the last exercise was fun and I learned a ton about extending Neo, working directly with the engine and so on, it’s not only slower (probably due to context switches and the relatively large transaction), but it’s hard to read, by magnitudes. As with a relational database, declarative languages like Cypher and SQL beat explicit programming hand down. If you ever have a need to migrate or aggregate and duplicate data from a relational database into Neo4j, have a look at apoc.load.jdbc. Select the stuff you need in one single context switch and then process as needed, either in a single transaction or also in batches and parallel.
For my music project, I’ll probably keep the ETL Tool around as I like the structure I created for the tool itself, but will rewrite the process from relational to graph based on APOC and plain SQL and Cypher statements, if it ever sees production of any kind.
Overall verdict: It took me a while to find a graph model I like and from which I am convinced I can actually draw some conclusions about the music I like, but after the graph started to resonate with me, it felt very natural and enjoyable.
Next step: Creating an Neo4j-OGM model for the different nodes.
Images in this post: Myself. Featured image – Markus Spiske.






No comments yet
Post a Comment