Die deutsche “Corona-Warn-App” CWA
Im Jahr 2020 passieren einige Dinge, die wohl kaum ein Mensch Ende des vergangenen Jahres hätte ahnen können. Die COVID-19 Pandemie ist es nicht… Führende Stimmen warnten schon lange. Die Pandemie ist allerdings Auslöser für vieles. So auch für die deutsche Variante der aktuell überall erscheinenden Corona-Tracing-Apps, die “Corona-Warn-App” beziehungsweise kurz CWA die nun von SAP entwickelt und in Zukunft von der Telekom betrieben werden wird.
Zu meiner Person: Ich bin seit 20 Jahren Java-Entwickler, Autor des deutschsprachigen Spring Boot Buchs und beruflich in der Open-Source Entwicklung tätig. Bereits Ende März äußerte ich mich sehr kritisch und negativ über mögliche Anwendungen aus Deutschland, ihre Implikationen auf Datenschutz, Anonymität, Verfolgbarkeit und mehr. Generell hat mich das Tempo der Maßnahmen Ende März eiskalt überrascht und auch stellenweise überfordert.
Ganz herzlichen Dank an Daniel, Tim, Michael, André, Jens, Falk und Sandra für das aufmerksame Lesen und das Feedback zu meinen Tippfehlern.
Ich möchte gar nicht lange über den Sinn und Nutzen von “Apps” im “Kampf gegen Corona” diskutieren. Das primäre Ziel dieser Apps ist das Nachverfolgbarmachen von Kontaktstrecken: Welche Person hielt sich für längere Zeit in der Nähe welcher anderen Personen auf? Erkrankt eine der Personen in diesen Kontaktketten, so können alle Personen der Kette informiert werden, dass sie Kontakt mit einer möglicherweise infizierten Person hatten. Die Konsequenzen dessen mögen unterschiedlich ausgeprägt sein, idR. wird es wohl auf eine mehr oder weniger nachdrücklich empfohlene Quarantäne hinauslaufen, gegebenenfalls angeordnete Tests.
Betrachtet werden im folgenden die Quelltexte der Corona-Warn-App. Genauer gesagt die in der Programmiersprache Java geschriebenen und mit dem Spring Framework umgesetzten Bestandteile des Backends.
Gastvorlesung an der FH-Aachen
Am 15. Juni durfte ich einen Gastvortrag an der FH-Aachen zum Thema Corona-Warn-App halten. Dieser wurde auf Youtube veröffentlicht:
Tracking oder tracing, zentral oder dezentral?
Tracking bezeichnet hier die Nachverfolgung einzelner Benutzer, durch regelmässiges Speichern des Aufenthaltsortes über die GPS-Daten eines unterstützten Smartphones. Tracking erfolgt in der Regel zentral: Individuelle Spuren einzelner Personen entstehen. Auch wenn viele Menschen dies täglich durch die Nutzung sozialer Medien mit aktivierten Ortungsdiensten tun, gewinnt es in den Händen des Staates noch einmal eine andere Bedeutung. Werden wir immer in einer Demokratie leben?
Daher wird in den Leitlinien der Europäischen Union zur Gewährleistung der uneingeschränkten Einhaltung der Datenschutzstandards durch Mobil-Apps zur Bekämpfung der Pandemie auch explizit von zentraler Speicherung der Standortdaten von Personen abgeraten:
Begrenzte Nutzung personenbezogener Daten: Die Apps sollten den Grundsatz der Datenminimierung einhalten, dem zufolge ausschließlich erforderliche personenbezogene Daten verarbeitet werden dürfen und die Verarbeitung auf das für den jeweiligen Zweck notwendige Maß beschränkt ist. Die Kommission ist der Ansicht, dass Standortdaten für die Ermittlung von Kontaktpersonen nicht erforderlich sind und dafür auch nicht verwendet werden sollten.
Datensicherheit: Die Daten sollten auf dem Gerät der betroffenen Person gespeichert und verschlüsselt werden.
Was ist die Alternative? Die Firmen Apple und Google haben sich auf ein Verfahren geeinigt, dass das sogenannte Decentralized Privacy-Preserving Proximity Tracing (DP3T) für Smartphones mit aktuellen iOS beziehungsweise Android-Betriebssystemen über Bluetooth umsetzt.
Im Detail beschrieb Heise.de die Funktionsweise unter dem Titel: Corona-Tracking: Wie Contact-Tracing-Apps funktionieren, was davon zu halten ist bereits im April.
Die Kurzform des ganzen ist ungefähr diese:
- Die Telefone generieren alle 24 Stunden einen temporären Schlüssel (TEK) und verschlüsseln diesen und speichern ihn auf dem Gerät.
- Aus diesem TEK werden weitere Schlüssel (RPIK) erzeugt, und zwar rollierend. Mit diesen werden Identifizierungsmerkmale generiert (Ephemeral ID beziehungsweise EphID genannt). Diese werden über Bluetooth abgestrahlt
- Aus den EphIDs kann nicht der TEK ermittelt werden beziehungsweise nicht das Gerät, dass die Schlüssel abgestrahlt hat
- Andere Geräte fangen diese EphIDs auf und speichern diese ebenfalls lokal
- Wird eine Benutzerin positiv auf COVID-19 getestet, so kann sie das in der App eingeben. Zu diesem Zeitpunkt werden die TEKs der letzten 14 Tage auf einen zentralen Server hochgeladen und von dort an als “Diagnose Schlüssel” bezeichnet. Ein Rückschluss auf die erkrankte Person ist nicht möglich, da die ursprünglichen TEKs alle 24 Stunden neu generiert werden.
- Der zentrale Server wird nun nach Prüfung den Diagnose Schlüssel an alle teilnehmenden Smartphones ausstrahlen. Diese Geräte können die gesammelten und lokal gespeicherten EphIDs von anderen Geräten, die in der Nähe waren, nun entschlüsseln, wenn diese ursprünglich mit dem TEK des diagnose Schlüssels verschlüsselt wurden. Ist dies der Fall, weiß die Benutzerin des Smartphones, dass sie – oder ihr Gerät – in der Nähe eines Smartphones war, das einer infizierten Person gehört
Die CWA braucht also mindestens folgende Bestandteile:
- Schnittstellen zum Betriebssystem moderner Smartphones: Diese stellen Apple und Google bereit.
- Ein Frontend dazu. Das, was allgemein in diesen Zeiten als “App” betrachtet wird.
- Ein Backend, das mindestens Komponenten enthält, die TEKs entgegen nehmen, verifizieren und anschließend an Teilnehmern des Systems ausstrahlen
Eine Komponente, die eine persönliche Anmeldung eines Benutzers am System enthält ist ausdrücklich nicht notwendig.
In Deutschland werden die letzt genannten Komponenten von einem Konsortium der Deutschen Telekom und SAP entwickelt und das als Open Source Anwendung, vollumfänglich verfügbar auf Github als Corona-Warn-App, inklusive der Projektdokumentation. Wie gesagt, eines der Dingen, die 2019 sicherlich höchst unwahrscheinlich waren.
Meine persönliche Meinung: So wie es aktuell rund 80 Millionen Virologen und Epidemiologen gibt, soviel Softwareexperten mit einer Meinung sind zu erwarten (ich sollte noch mal auf mein Buch aufmerksam machen, kauft es, es ist sehr gut!): SAP und Telekom haben in diesem Umfeld wenig zu gewinnen: Es ist anzuerkennen und trägt für mich sehr zum Vertrauen in eine solche App bei, dass eine offene Entwicklung zumindest versucht wird, und das angefangen bei der wirklich guten Projektdokumentation, Softwarearchitekturbeschreibung, den Epics und Whitepapers, den Apps für iOS und Android sowie dem Quelltext des Servers, mit dem die Apps sprechen und dem Verifikationsserver.
Ich habe keine Expertise in der Anwendungsentwicklung für iOS beziehungsweise Android. Daher verweise ich für dieses Thema auf das Review von Roddi: Review der App, die Endanwender sehen.
Softwarearchitektur
Wir finden die relevante Softwarearchitektur in der Dokumentation unter Solution Architecture (Architektur der Lösung). Ich benutze dieselben Grafiken wie das CWA-Projekt, die unter Apache 2 License veröffentlicht wurden:
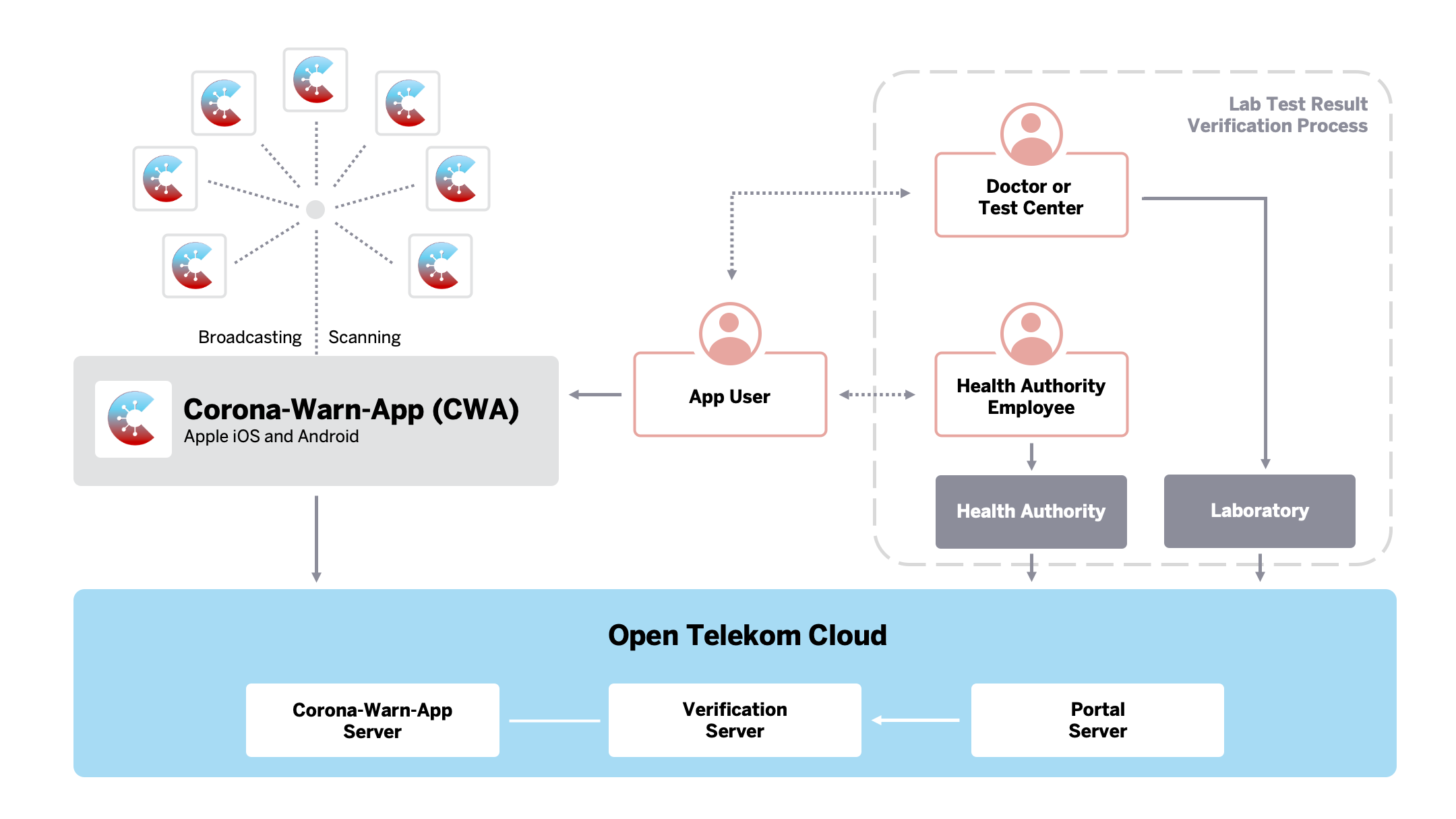
Oben links sehen wir die Komponenten auf dem Gerät der Nutzer: die CWA. In der “Open Telekom Cloud” sehen wir alle Serverkomponenten, die im folgenden weiter enthüllt werden:
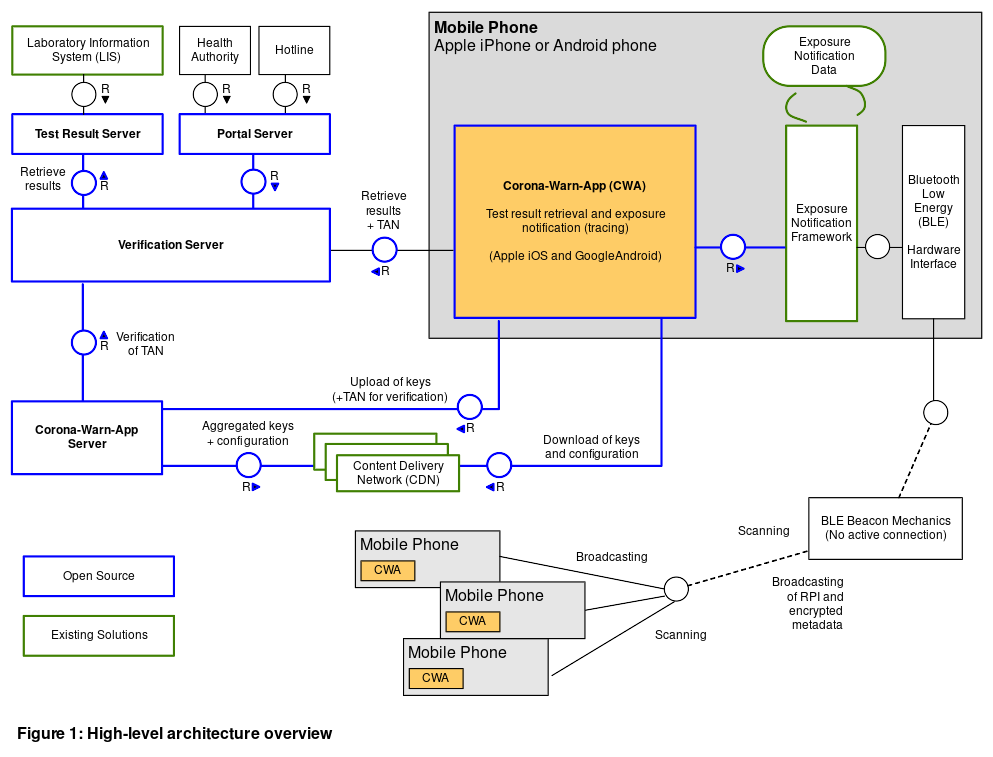
Diese Dokumente sprechen sicherlich nicht jeden Menschen an, für mich sind sie sehr aussagekräftig und genau richtig detailliert. Sie ermöglichen einen schnellen Zugang zu den Komponenten des Systems. Ich halte Zugänglichkeit in diesem Fall für essentiell!
Ich werde im folgenden die Komponenten “Corona-Warn-App-Server” (dieser nimmt die TEK infizierter Personen entgegen) und den “Verification Server” (dieser verifiziert die Infektion einer Person, die diese in die App einträgt, mit dem “Test Result Server”, auf dem die Daten des Gesundheitsamtes gespeichert sind) unter dem Standpunkt des beschriebenen Verfahrens betrachten und analysieren, ob mehr Daten als versprochen gespeichert werden oder nicht und ob offenkundige, grobe Schnitzer gemacht wurden.
Der Corona-Warn-App-Server
Update vom 3. Juni: Auf Twitter entsteht eine spannende Diskussion über das eigentliche Datenmodel selber: Thread sowie insbesondere meine Antworten und diese darin. Hier gibt es grundsätzlich 2 Bedenken: “Bleibt das DB Setup so in Produktion?” (Wenn ja, da stimme ich Alvar zu, wäre das schlecht), “Sollte so modelliert werden?” (vor diesem Commit hätte ich gesagt, ist nicht brilliant, aber ok… Die Änderungen danach sind so mittelgeil. Es wird gehofft, dass die “keys of infected user” aus dem Übertragungsprotokoll unique genug sind, um als Primary Key zu dienen und falls doch nicht, saveDoNothingOnConflicty YOLO. Also ich hätte das schon gern gewusst, wenn eine App-Instanz das Backend mit duplicate keys flutet.
Erste Frage: Wie ist es um Vollständigkeit und Inbetriebnahme bestellt? Mein erster Gedanke bei den umsetzenden Unternehmen wäre ein komplexes Enterprise-Deployment, mit Application-Server, Portalservern und mehr gewesen. Klassisches Java EE halt. Ich wurde positive von mehreren Java basierten Spring Boot-Anwendungen überrascht. Die Zielplattform der Anwendung ist Kubernetes, ebenfalls eine Lösung zur Automatisierung der Bereitstellung, Skalierung und Verwaltung von Anwendungen in sogenannten Containern. Kubernetes ist ebenfalls Opensource und wird im Fall der CWA in OpenShift betrieben. OpenShift verwaltet Rechenressourcen in privaten und öffentlichen Clouds.
Kann ich den Server lokal bauen und kompilieren, Java und das Buildtool vorausgesetzt?
Kurz: Ja!
> cwa-server git:(master) ./mvnw clean verify [INFO] Reactor Summary for server 0.5.3-SNAPSHOT: [INFO] [INFO] server ............................................. SUCCESS [ 1.301 s] [INFO] common ............................................. SUCCESS [ 0.066 s] [INFO] protocols .......................................... SUCCESS [ 4.354 s] [INFO] persistence ........................................ SUCCESS [ 11.746 s] [INFO] services ........................................... SUCCESS [ 0.326 s] [INFO] distribution ....................................... SUCCESS [ 14.035 s] [INFO] submission ......................................... SUCCESS [ 13.675 s] [INFO] ------------------------------------------------------------------------
Find ich erstmal gut. Das Readme beinhaltet Anweisungen, wie das ganze Dingen in Betrieb genommen werden kann, die Stand 31. Mai auch funktionieren. Ein herzhaftes `docker-compose up` bringt hervor:
80/tcp pgadmin_container 0.0.0.0:8000->8080/tcp, 0.0.0.0:8006->8081/tcp cwa-server_submission_1 0.0.0.0:8001->5432/tcp cwa-server_postgres_1 0.0.0.0:8003->8000/tcp cwa-server_objectstore_1 0.0.0.0:8004->8004/tcp cwa-server_verification-fake_1
Der submission-server
Basiert auf Spring Boot 2.3, dem aktuellsten Release. Die Wesentliche Abhängigkeiten sind spring-boot-starter-web sowie spring-boot-starter-security sowie Spring Boot Actuator und Micrometer und die Prometheus Anbindung. Mit den letzt genannten Komponenten können Metriken (u.a. Performance etc.) offen gespeichert werden.
Im commons befinden sich sowohl die implementierten Protokolle auf Basis von Protocol buffers als auch die Datenbankschicht.
Letztere setzt auf auf eine relationale Datenbank: Postgres. Ich halte das für eine vernünftige als auch transparente Wahl.
Gespeichert wird tatsächlich nur das, was im eingangs beschriebenen Prozess notwendig ist: Der zum Diagnosis Key erhobene Temporary Exposure Key.
Am Code selber gibt es einiges, dass ich persönlich nicht als “Best-Practices” sehen oder gar empfehlen würde. Wenn schon explizite `@EnableXXX` Konfiguration, dann richtig: Manuelle Auflistung aller Spring-Komponenten, um im Zweifelsfall sicher davor zu sein, dass eine Bibliothek über automatische Konfiguration unerwünschte Komponenten registriert. Vollständig irritierend finde ich die Suche nach Servlet-Komponenten: Zumindest im Sourcecode finde ich keine zusätzlichen Komponenten, die nicht bereits so gefunden werden würden. Lässt die Frage offen, ob die final paketierte App gegebenenfalls weitere Libraries beinhaltet.
Die Testabdeckung ist auf den ersten Blick gut, mit entsprechenden Mocks der Downstream-Services ist der Submission-Controller testbar.
Die Dokumentation lässt leider offen, was es mit dem numerischen, erforderlichen Header cwa-fake auf sich hat. Ich vermute er dient zum Testen der Apps. Ich würde dazu raten, diesen Code Bereich im Controller in Produktion zu entfernen.
Von Johannes kam der Hinweis auf die Stelle der Dokumentation, die ich übersehen habe: Fake Submissions:
In order to protect the privacy of the users, the mobile app needs to send fake submissions from time to time. The server accepts the incoming calls and will treat them the same way as regular submissions. The payload and behavior of fake and real requests must be similar, so that 3rd parties are unable to differentiate between those requests. If a submission request marked as fake is received by the server, the caller will be presented with a successful result.
Das Ziel der Übung ist, “weißes Rauschen” zu Erzeugen. Sowohl in Bezug auf die Requests selber, als auch in Bezug auf die Antwortzeiten (Das kann gegen Timing-Angriffe schützen.
Der distribution Service
Die Aufgabe dieses Service ist die Verteilung bestätigter Diagnose Keys an sogenannte CDNs: “Content delivery networks”. Das sind speziell auf die Auslieferung von statischen Inhalten ausgelegte Dienste, die das in der Regel sehr schnell und sehr zuverlässig tun und die oftmals auch speziell auf Regionen ausgeprägt werden können.
Ebenfalls setzt dieser Service die Anforderung um, dass gespeicherte Diagnosis Keys nach 14 Tagen gelöscht werden.
Der distribution Service ist schlussendlich ein Kommandozeilen-Programm. Er muss von außen orchestriert werden. Nach Start werden alte Schlüssel gelöscht (die SQL-Abfrage ist nachvollziehbar und in Form eines Spring Data Repositories implementiert), alle neuen Schlüssel zusammengestellt und anschließend in einem S3 kompatiblen Cloud-Speicher gespeichert. In Produktion wird dieser in der in Deutschland gehosteten Telekom-Cloud liegen, im Test ist es ein “Zenko/Cloudserver”, der lokal in Docker gestartet werden kann. Optional werden Debug / Testdaten generiert. Danach endet das Progrmam.
Auf den ersten Blick fand ich die Entscheidung seltsam und hätte einen dauerhaft laufenden Service gewählt und die Prozesse mit den Mitteln des Spring-Frameworks gesteuert… Im Zweifelsfall mit den entsprechenden @Schedule-Annotationen. Metriken würden dabei ebenfalls automatisch anfallen und gesammelt werden können.
Ich kann nicht beurteilen, ob die andere Entscheidung besser ist. Sie erfordert auf jeden Fall weitere Konfiguration in der Kubernetes-Zielplattform um den Dienst anzustoßen.
Die Testabdeckung ist auf den ersten Blick gut.
Zwischenfazit zum Warn-App-Server
Es gibt vieles, das ich persönlich im Corona-Warn-App-Server anders machen würde. Aber ist er grundsätzlich “kaputt” oder unsicher? Sicherlich nicht. Die Architektur ist gut dokumentiert und an einem Sonntagnachmittag nachvollziehbar. Das ist gut: Übermässige Komplexität erhöht Fehlerwahrscheinlichkeiten oder schafft Lücken, Dinge zu verstecken.
Der Server speichert keine weiteren Daten als die notwendigen. Es wäre interessant, die Konfiguration der Orchestrierung des ganzen für die Produktionsumgebung zu sehen. Wird die PostgreSQL Datenbank on-disk verschlüsselt? Wird sie gegebenenfalls repliziert? Wie sind die Object-Stores geschützt?
Der Corona-Warn-App Verification Server
Die Verifikation eines Benutzers, der seine Erkrankung und das Testergebnis an die App melden möchte, erfolgt mit Hilfe eines TAN-Verfahren. Der Datenfluss ist in Solution Architecture detailliert erklärt. Wichtig ist hier, dass der Verification Server keine personenbezogenen Daten speichert. Er nutzt zur Bestätigung des Test einen weiteren Dienst. Diesen habe ich nicht angeschaut.
Die Liste der Abhängigkeiten des Verification Servers ist deutlich größer: Von Lombok an angefangen über Guava zu OpenAPI UI und zum Feign-Client zur deklarativen Anbindung von Webservices. Gut, der Labserver hätte auch anders angebunden werden können… Aber passt schon.
Der Service speichert – ebenfalls in einer PostgreSQL-Datenbank – eine “AppSession” sowie die empfangenen TANs.
Warum der Verification Server Liquibase und der Warn Server Flyway zur Datenbankmigration nutzt? Unklar. Vermutlich unterschiedliche Teams.
Auch hier werden keine Daten gespeichert, die direkt oder einfach einer Person zugeordnet werden können, das Prinzip der Datensparsamkeit wird beachtet.
Fazit
Wer ein “Domain Driven Design”-Leuchtturm-Projekt erwartet, ist an der falschen Stelle. Die von mir betrachteten Services sind sicherlich keine hervorstechenden Projekte, die durch die Bank Best-Practices zeigen. Aber sie sind solide, gut zugänglich, vollumfänglich dokumentiert und insbesondere frei von künstlerischen Kapriolen. (der Art “Lass mal eigenen Schlüsselmechanismus bauen oder einen eigenen Persistenzlayer”).
Das Decentralized Privacy-Preserving Proximity Tracing (DP3T) Konzept wirkt für mich schlüssig, die implementierten Backend-Services speichern erstmal nur die notwendigen Daten um den eingangs erklärten Prozess zu unterstützen.
Einige Fragen habe ich bereits im Text gestellt. Reproducible Builds und Nachvollziehbarkeit, wer wann welchen Build deployed hat sind noch zu ergänzen.
Während ich die “Datenspende-App” des Robert-Koch-Instituts für eine Katastrophe halte (sowohl von der Umsetzung und des Timings im April, siehe hier und hier), würde ich die Corona-Warn-App des Landes wahrscheinlich nutzen. Meine größte Sorge wäre Stand heute vermutlich der Stromverbrauch und in zweiter Hinsicht, der Nutzen: Was passiert, wenn ich in Kontakt mit infizierten Personen kam? Das System ist so ausgelegt, dass der Server nicht weiß, wer ich bin. Es setzt also auf den gesunden Menschenverstand derjenigen, die gewarnt werden. Dass die gegebenenfalls in Quarantäne gehen, Kontakte wieder vermeiden. Mehr nicht. Vielleicht wäre es sinnvoll, eine Warnung direkt mit einem kostenlosen Test-Coupon zu verschicken.
Am Ende darf also bezweifelt werden, dass es eine technische Lösung für die Corona-Pandemie gibt. Jürgen Geuter aka tante, den ich sehr schätze, schrieb bereits im April, ob diese Apps nötig sind.. Ich halte den Artikel nach wie vor für lesenswert, über Technologie hinaus. Ebenfalls sehr lesenswert, jedoch auf Englisch, ist der folgende Text: The long tail of contact tracing (societal impact of CT).